Scheduler workflow
When we use K8S clusters, we often need to create, modify, and delete Deployment Controllers. K8S will create, destroy, and reschedule Pods on the appropriate nodes. This scheduling process is implemented through the K8S Scheduler scheduler. Schduler’s workflow is shown below:
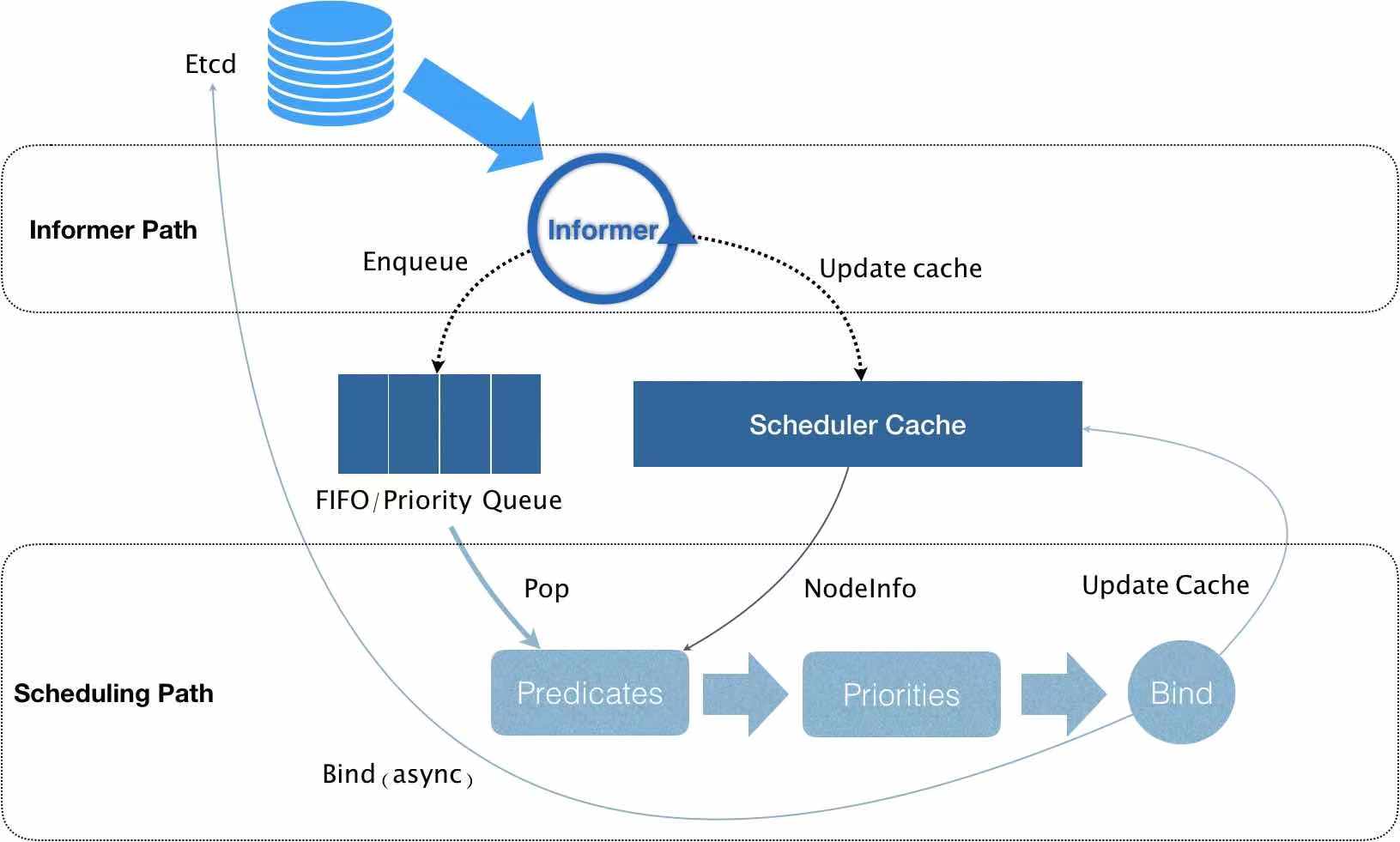 The Informer component has been monitoring changes in Pod information in etcd. To be precise, it is monitoring changes in the Spec.nodeName field in Pod information. Once it detects that this field is empty, it is considered that there are Pods in the cluster that have not been scheduled to Node. This At this time, the Informer starts to add the information of this Pod to the queue and updates the Scheduler Cache at the same time. Next, the Pod information is dequeued from the queue and enters the Predicates (preselection stage). In this stage, a series of preselection algorithms are used to select nodes in the cluster that are suitable for Pod operation, and then enters the Priorities (preference stage) with this information. In the same way, this stage uses a series of optimization algorithms to score each Node as suitable for the Pod scheduling, and finally selects the most suitable (that is, the highest-scoring) Pod running node in the cluster, and finally selects this node. The node is bound to the Pod and the cache is updated to implement Pod scheduling.
The Informer component has been monitoring changes in Pod information in etcd. To be precise, it is monitoring changes in the Spec.nodeName field in Pod information. Once it detects that this field is empty, it is considered that there are Pods in the cluster that have not been scheduled to Node. This At this time, the Informer starts to add the information of this Pod to the queue and updates the Scheduler Cache at the same time. Next, the Pod information is dequeued from the queue and enters the Predicates (preselection stage). In this stage, a series of preselection algorithms are used to select nodes in the cluster that are suitable for Pod operation, and then enters the Priorities (preference stage) with this information. In the same way, this stage uses a series of optimization algorithms to score each Node as suitable for the Pod scheduling, and finally selects the most suitable (that is, the highest-scoring) Pod running node in the cluster, and finally selects this node. The node is bound to the Pod and the cache is updated to implement Pod scheduling.
Predicates pre-selection process
The predicates algorithm mainly filters the nodes in the cluster and selects a group of nodes that are suitable for the current pod operation. There are many pre-selection algorithms for filtering nodes, such as: CheckNodeConditionPredicate (checking whether the node can be scheduled), PodFitsHost (checking whether the pod.spec.nodeName field has been specified), PodFitsHostPorts (checking whether the port node required by the pod can be provided), etc., pre-selection algorithm The execution sequence is as follows:
var (
predicatesOrdering = []string{
CheckNodeConditionPred,
CheckNodeUnschedulablePred,
GeneralPred,
HostNamePred,
PodFitsHostPortsPred,
MatchNodeSelectorPred,
PodFitsResourcesPred,
NoDiskConflictPred,
PodToleratesNodeTaintsPred,
PodToleratesNodeNoExecuteTaintsPred,
CheckNodeLabelPresencePred,
CheckServiceAffinityPred,
MaxEBSVolumeCountPred,
MaxGCEPDVolumeCountPred,
MaxCSIVolumeCountPred,
MaxAzureDiskVolumeCountPred,
CheckVolumeBindingPred,
NoVolumeZoneConflictPred,
CheckNodeMemoryPressurePred,
CheckNodePIDPressurePred,
CheckNodeDiskPressurePred,
MatchInterPodAffinityPred}
)
This order can be overridden by the configuration file. The user can specify a configuration file similar to this to modify the execution order of the preselection algorithm:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts", "order": 2},
{"name" : "PodFitsResources", "order": 3},
{"name" : "NoDiskConflict", "order": 5},
{"name" : "PodToleratesNodeTaints", "order": 4},
{"name" : "MatchNodeSelector", "order": 6},
{"name" : "PodFitsHost", "order": 1}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
],
"hardPodAffinitySymmetricWeight" : 10
}
For a pod, a group of nodes concurrently executes the predicates preselection algorithm (note that multiple nodes execute this group of algorithms in sequence at the same time, rather than one node executing multiple algorithms at the same time). Once a node executes the preselection in sequence During the algorithm, if an algorithm fails to execute, the node will be kicked out directly and no further processes will be executed. After such filtering, the node pre-selection process is implemented, and the remaining group of nodes will eventually enter the next stage: the priorities selection process. The optimization process will be introduced in detail in the next chapter.
Concurrent process of predicate
The execution process of the pre-selection algorithm is implemented through the concurrent execution of multiple nodes:
pkg/scheduler/core/generic_scheduler.go:389
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {
checkNode := func(i int) {
// PodFitsOnNode is the logic for executing the pre-selection algorithm.
fits, failedPredicates, err := podFitsOnNode(
//……
)
if fits {
length := atomic.AddInt32(&filteredLen, 1)
filtered[length-1] = g.cachedNodeInfoMap[nodeName].Node()
}
}
workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
if len(filtered) > 0 && len(g.extenders) != 0 {
for _, extender := range g.extenders {
// Logic of extenders
}
}
return filtered, failedPredicateMap, nil
}
The workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode) function is used to execute N independent work processes concurrently. This refers to opening 16 go coroutines to concurrently process int(allNodes) (that is, node number) tasks, the content of each task is to call the checkNode method. As can be seen from the above code, calling the checkNode method is calling the podFitsOnNode method inside, which also executes the logic of the preselection algorithm. The implementation of the podFitsOnNode method is explained in detail below.
Use the podFitsOnNode function to implement a node pre-selection process
pkg/scheduler/core/generic_scheduler.go:425
func podFitsOnNode(
pod *v1.Pod,
meta algorithm.PredicateMetadata,
info *schedulercache.NodeInfo,
predicateFuncs map[string]algorithm.FitPredicate,
nodeCache *equivalence.NodeCache,
queue internalqueue.SchedulingQueue,
alwaysCheckAllPredicates bool,
equivClass *equivalence.Class,
) (bool, []algorithm.PredicateFailureReason, error) {
podsAdded := false
// The pre-selection algorithm is called twice in a loop here. The reason involves the preemption logic of the pod, which will be explained in detail later.
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
// Only the first loop will call the add Nominated Pods function
if i == 0 {
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
eCacheAvailable = equivClass != nil && nodeCache != nil && !podsAdded
// predicates.Ordering() gets a []string, a collection of predicate names
for predicateID, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []algorithm.PredicateFailureReason
err error
)
// If predicate Funcs has this key, this predicate is called; that is to say, if predicate Funcs is defined with any other name, it will be ignored because the predicate Key is specified internally.
if predicate, exist := predicateFuncs[predicateKey]; exist {
if eCacheAvailable {
fit, reasons, err = nodeCache.RunPredicate(predicate, predicateKey, predicateID, pod, metaToUse, nodeInfoToUse, equivClass)
} else {
// the predicate function is actually called
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
}
if err != nil {
return false, []algorithm.PredicateFailureReason{}, err
}
if !fit {
// ……
}
}
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}
The above code can be divided into two parts: **1. The addNominatedPods function is called in the first for loop. This function adds higher priority preemption type Pods to the Scheduler cache first. 2. Both the first and second loops call the predicate function, where the logic of the Predicates preselection algorithm is actually executed. ** So why loop twice? Because the first loop and the second loop do slightly different things. It can be seen from the code that the first loop calls the addNominatedPods function more than the second loop. This function passes in the pod and the pod queue currently waiting for scheduling, filters out the pod information in the queue that satisfies the pod.Status.NominatedNodeName field is not empty and has a priority greater than or equal to the current pod, and adds it to the Scheduler cache. That is to say, the pod must meet the following two conditions at the same time before the pod is added to the Scheduler cache: 1. The pod.Status.NominatedNodeName field is not empty. 2. The priority is greater than or equal to the current pod The reasons for adding this type of pod to the Scheduler cache and then performing the preselection algorithm are: In the logic of pod preempting a node, the pod with higher priority preempts the node first. After the preemption is successful, the pod.Status.NominatedNodeName field is set to the current node. After the setting is completed, the scheduler runs to execute the scheduling logic of the next pod. This At this time, the pod is probably not actually running on the node (not necessarily in the running state). Therefore, there is actually no information about this type of pod in the Scheduler cache, so when scheduling the current pod, it will be affected by these high-priority pods (there are pod affinity, anti-affinity and other dependencies between pods) ), So we must first assume that this type of high-priority pod is already running in this node. There are two processes: manually calling the addNominatedPods function to add other high-priority pods to the cache and then executing the preselection algorithm. Not only that, in order to be foolproof (in case these high-priority pods eventually fail to run on this node), these high-priority pods must be excluded and the pre-selection algorithm must be executed again. In this way, no matter whether other high-priority pods are on this node or not, this pod can be scheduled on these nodes without conflict.
Single predicate execution process
The predicate function is a collection of preselected algorithms:
```go
var (
predicatesOrdering = []string{
CheckNodeConditionPred,
CheckNodeUnschedulablePred,
GeneralPred,
HostNamePred,
PodFitsHostPortsPred,
MatchNodeSelectorPred,
PodFitsResourcesPred,
NoDiskConflictPred,
PodToleratesNodeTaintsPred,
PodToleratesNodeNoExecuteTaintsPred,
CheckNodeLabelPresencePred,
CheckServiceAffinityPred,
MaxEBSVolumeCountPred,
MaxGCEPDVolumeCountPred,
MaxCSIVolumeCountPred,
MaxAzureDiskVolumeCountPred,
CheckVolumeBindingPred,
NoVolumeZoneConflictPred,
CheckNodeMemoryPressurePred,
CheckNodePIDPressurePred,
CheckNodeDiskPressurePred,
MatchInterPodAffinityPred}
)
predicatesOrdering polls the function names in this array for sequential calls. Here are some examples of preselection algorithms:
- NoDiskConflict: Determine whether the volume information of the current pod conflicts with the volume information of the node. pkg/scheduler/algorithm/predicates/predicates.go:277
func NoDiskConflict(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
for _, v := range pod.Spec.Volumes {
for _, ev := range nodeInfo.Pods() {
if isVolumeConflict(v, ev) {
return false, []algorithm.PredicateFailureReason{ErrDiskConflict}, nil
}
}
}
return true, nil, nil
}
二、PodMatchNodeSelector:Determine whether the node Selector field of the current pod matches the node information pkg/scheduler/algorithm/predicates/predicates.go:852
// PodMatchNodeSelector checks if a pod node selector matches the node label.
func PodMatchNodeSelector(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
node := nodeInfo.Node()
if node == nil {
return false, nil, fmt.Errorf("node not found")
}
if podMatchesNodeSelectorAndAffinityTerms(pod, node) {
return true, nil, nil
}
return false, []algorithm.PredicateFailureReason{ErrNodeSelectorNotMatch}, nil
}
三、PodFitsHost:Determine whether the Spec.Node Name field of the current pod matches the name of the node pkg/scheduler/algorithm/predicates/predicates.go:864
// PodFitsHost checks if a pod spec node name matches the current node.
func PodFitsHost(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
if len(pod.Spec.NodeName) == 0 {
return true, nil, nil
}
node := nodeInfo.Node()
if node == nil {
return false, nil, fmt.Errorf("node not found")
}
if pod.Spec.NodeName == node.Name {
return true, nil, nil
}
return false, []algorithm.PredicateFailureReason{ErrPodNotMatchHostName}, nil
}
At this point, the execution logic of the Predicates preselection algorithm ends, and the execution logic of the Priorities optimization algorithm will be entered later.