Scheduler workflow
When we use K8S clusters, we often need to create, modify, and delete Deployment Controllers. K8S will create, destroy, and reschedule Pods on the appropriate nodes. This scheduling process is implemented through the K8S Scheduler scheduler. Schduler’s workflow is shown below:
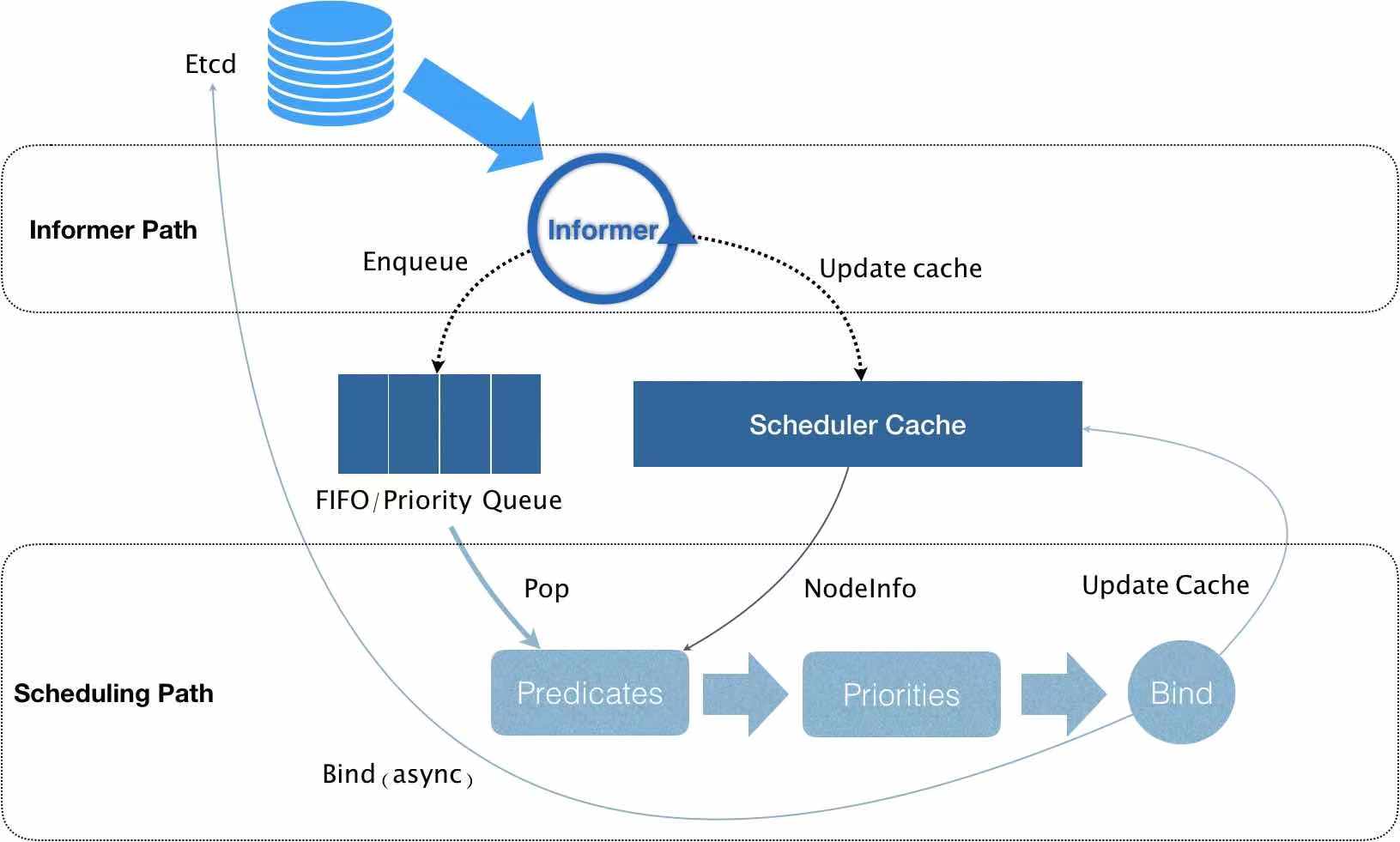 The Informer component has been monitoring changes in Pod information in etcd. To be precise, it is monitoring changes in the Spec.nodeName field in Pod information. Once it detects that this field is empty, it is considered that there are Pods in the cluster that have not been scheduled to Node. This At this time, the Informer starts to add the information of this Pod to the queue and updates the Scheduler Cache at the same time. Next, the Pod information is dequeued from the queue and enters the Predicates (preselection stage). In this stage, a series of preselection algorithms are used to select nodes in the cluster that are suitable for Pod operation, and then enters the Priorities (preference stage) with this information. In the same way, this stage uses a series of optimization algorithms to score each Node as suitable for the Pod scheduling, and finally selects the most suitable (that is, the highest-scoring) Pod running node in the cluster, and finally selects this node. The node is bound to the Pod and the cache is updated to implement Pod scheduling.
The Informer component has been monitoring changes in Pod information in etcd. To be precise, it is monitoring changes in the Spec.nodeName field in Pod information. Once it detects that this field is empty, it is considered that there are Pods in the cluster that have not been scheduled to Node. This At this time, the Informer starts to add the information of this Pod to the queue and updates the Scheduler Cache at the same time. Next, the Pod information is dequeued from the queue and enters the Predicates (preselection stage). In this stage, a series of preselection algorithms are used to select nodes in the cluster that are suitable for Pod operation, and then enters the Priorities (preference stage) with this information. In the same way, this stage uses a series of optimization algorithms to score each Node as suitable for the Pod scheduling, and finally selects the most suitable (that is, the highest-scoring) Pod running node in the cluster, and finally selects this node. The node is bound to the Pod and the cache is updated to implement Pod scheduling.
Priority selection process
The entire process is as follows:
Pass the Pod list and Node list that need to be scheduled to various optimization algorithms for scoring, and finally integrate them into the result set HostPriorityList:
type HostPriority struct {
Host string
Score int
}
type HostPriorityList []HostPriority
This HostPriorityList array saves the name of each Node and its corresponding score. Finally, the Node with the highest score is selected to bind and schedule the Pod. So how exactly does the optimization algorithm work? Let’s take a look at the preferred algorithm structure PriorityConfig in the source code:
type PriorityConfig struct {
Name string
Map PriorityMapFunction
Reduce PriorityReduceFunction
// TODO: Remove it after migrating all functions to
// Map-Reduce pattern.
Function PriorityFunction
Weight int
}
The optimization algorithm consists of a series of PriorityConfig (that is, PriorityConfig array). Each Config represents an algorithm. Config describes the name, weight, Function (a type of optimization algorithm function), Map-Reduce (Map and Reduce components appears, is another preferred algorithmic function type). The Pod that needs to be scheduled performs each optimal algorithm (A) on each suitable Node (N) to score, and finally obtains a two-dimensional array, the elements of which are A1N1, A1N2, A1N3…, and the rows represent one algorithm corresponding to different The scores calculated by the Node, the columns represent the scores of the same Node corresponding to different algorithms:
| N1 | N2 | N3 | |
|---|---|---|---|
| A1 | { Name:“node1”,Score:5,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:3,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:1,PriorityConfig:{…weight:1}} |
| A2 | { Name:“node1”,Score:6,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:2,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:3,PriorityConfig:{…weight:1}} |
| A3 | { Name:“node1”,Score:4,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:7,PriorityConfig:{..weight:1.}} | { Name:“node3”,Score:2,PriorityConfig:{…weight:1}} |
Finally, combine the results into a one-dimensional array HostPriorityList:
HostPriorityList =[{ Name:"node1",Score:15},{ Name:"node2",Score:12},{ Name:"node3",Score:6}]
This completes the process of scoring the optimal algorithm for each Node.
Function type optimization algorithm
There are two specific optimization algorithms. The first priority function type optimization algorithm will be introduced first.
type PriorityFunction func(pod *v1.Pod, nodeNameToInfo map[string]*schedulercache.NodeInfo, nodes []*v1.Node) (schedulerapi.HostPriorityList, error) {
...
...
...
//traverse each preferred algorithm struct
for i := range priorityConfigs {
// If the i-th priority Configs is configured with a Priority Function, it is called;
if priorityConfigs[i].Function != nil {
wg.Add(1)
// Here index is i, which means starting to call the i-th algorithm, and the result obtained is placed in the result set of the i-th result.
go func(index int) {
defer wg.Done()
var err error
// So the results[index] here is easy to understand; the index of priorityConfigs[index] later is also index.
// What is expressed here is that there is a PriorityFunction in the Nth preferred configuration, then the calculation result of this Function is saved in
//In the Nth grid of results;
//Here we start calling the PriorityFunction type optimization algorithm
results[index], err = priorityConfigs[index].Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i)
} else {
// If Function is not defined, the Map-Reduce method is used, which is explained in detail in the next section
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
...
}
}
...
...
...
}
Map-Reduce prioritize algorithm
The second algorithm type is PriorityMapFunction and PriorityReduceFunction, which appear in pairs. First, parallel calculations are performed through the Map function, and then the calculation results are collected through the Reduce function.
// Parallelize Until is client-go's concurrency toolkit. Here it means that up to 16 threads can be opened to process the number of nodes. Focus on the last parameter, which is an anonymous function
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
// The index here is [0, len(nodes)-1], which is equivalent to traversing all nodes
nodeInfo := nodeNameToInfo[nodes[index].Name]
// This for loop traverses all the preferred configurations. If it is a Function type, it will be skipped and the new logic will continue
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
// Because the Fucntion type has been run before, skip it here.
continue
}
var err error
// The i here is complementary to the previous Function. The elements in results that are not assigned in the Function are assigned here
// Notice that a Map function is called here and is directly assigned to results[i][index]. The index here is the first line.
// The formal parameters of the anonymous function implement the score calculation of all nodes corresponding to a preferred algorithm through Parallelize Until.
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Host = nodes[index].Name
}
}
})
for i := range priorityConfigs {
// If the Reduce function is not defined, it will not be processed
if priorityConfigs[i].Reduce == nil {
continue
}
wg.Add(1)
go func(index int) {
defer wg.Done()
// Call the Reduce function
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if klog.V(10) {
for _, hostPriority := range results[index] {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), hostPriority.Host, priorityConfigs[index].Name, hostPriority.Score)
}
}
}(i)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
The logic of Map-Reduce is generally consistent with the logic of the Function-type optimization algorithm. The idea is to use the Pod to traverse each Node and call the optimization algorithm to calculate the score of each Node to obtain the two-dimensional array corresponding to the Node-Score mentioned above. Let’s start integrating the array (Combine).
Combine combined result set
The process of Combine is very simple. You only need to perform weighted sum statistics on the scores of Node names with the same name.
// Summarize all scores.
// This result is similar to the previous results. The result is used to store the Score of each node. There is no need to distinguish the algorithm here
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
// Loop execution len(nodes) times
for i := range nodes {
// First fill the result with the names of all nodes, and initialize the Score to 0
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
// There are as many Scores as there are priority Config executed, so it is traversed len(priority Configs) times here
for j := range priorityConfigs {
// The result scores of each algorithm corresponding to the i-th node are weighted and accumulated
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
return result, nil
Finally, we get the one-dimensional array HostPriorityList, which is the collection of HostPriority structures mentioned earlier:
type HostPriority struct {
Host string
Score int
}
type HostPriorityList []HostPriority
In this way, the scoring Priority optimization process for each Node is implemented.