1、相关背景
随着 K8s 单集群规模不断扩大(节点数达到4000+),我们在运营过程中发现 apiserver 逐渐成为集群的性能瓶颈,容易出现请求无响应、响应慢、请求拒绝等问题,甚至导致集群雪崩,引发现网故障。 以下详细说明如何快速定位和排查 apiserver 性能问题。
2、原因分类
高负载导致访问慢
apiserver高负载
-
内存:一般是因为List请求和资源较多,序列化开销也比较大
-
CPU:qps或List请求较高时,序列化反序列化开销较大
-
流量:大量List请求导致大流量(可通过监控和审计确认来源)
etcd高负载
-
流量:一般是由于客户端发起大量List请求,并且没走apiserver缓存(即没指定ResourceVersion)
-
内存:一般是由于流量较大
-
CPU:流量比较大/watcher比较多等
-
IO延时:CBS异常抖动,母机负载高等
-
慢查询:客户端有全量资源的List操作/写请求比较多
客户端高负载
- 客户端CPU/内存/带宽高负载,请求发起和接收回包较慢
引发限速
apiserver限速
-
inflight限速(通过监控指标 apiserver_current_inflight_requests 确认):apiserver默认限速写200( –max-mutating-requests-inflight),读400( –max-requests-inflight).
-
1.20+ APF限速 (通过监控指标 apiserver_flowcontrol_rejected_requests_total、apiserver_flowcontrol_request_execution_seconds_bucket 确认): 1.20默认开启APF限速,默认会通过namespace,user等进行限速,kube-system 下的 user 和系统组件(kcm,scheduler等)默认限速阈值较高,普通 serviceaccount 限速阈值较低,在 apiserver 响应慢时有概率触发,现象可能会比较诡异(比如部分组件或者 serviceaccount token 请求较慢或不响应)。
-
loopback client 限速,低版本(1.12及以下)apiserver 会通过 loopback client 请求自身(qps 50),使用 serviceaccount 认证访问 kube-apiserver 时,如果并发过高,则可能导致限速(此时 apiserver 日志中常见大量 Create tokenreviews 30s的慢查询),参考炒饭大佬的:一次ServiceAccount导致的apiserver雪崩案例分析
客户端限速
- client-go默认qps 5, kcm默认20,scheduler默认50: 如果触发限速,则日志级别4以上(高版本client-go日志级别3以上)可以看到客户端日志中有打印Throttling request took相关日志
外部组件异常
-
通过webhook进行认证授权时webhook响应慢
-
admission webhook响应慢:api-server 日志中会打印Call xxx webhook相关字样,如: Call Audit Events webhook

3、排查方法
观察 APIServer 监控
-
查看机器的 CPU、内存、负载、流量监控是否异常
-
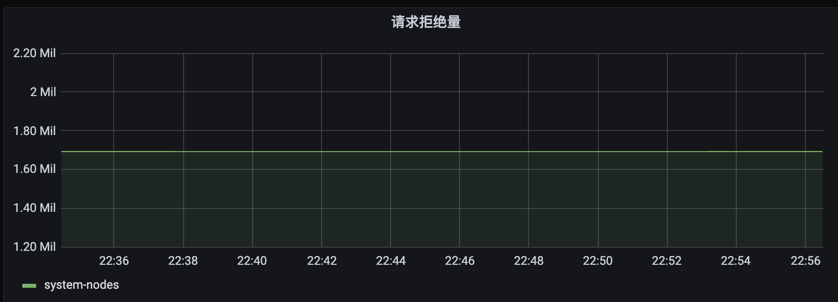
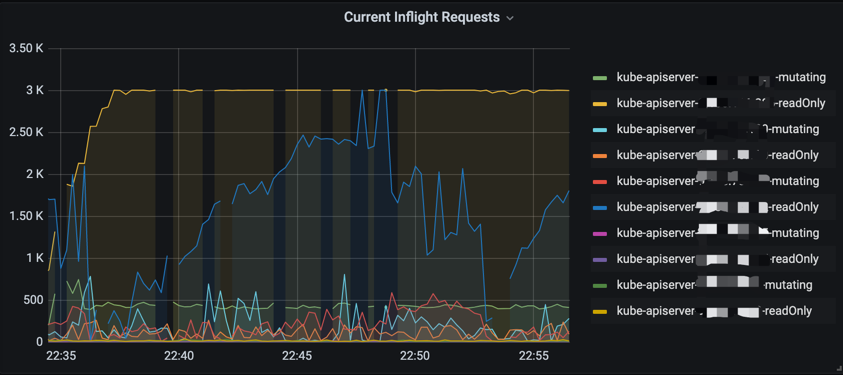
inflight 相关指标,默认限速写200( –max-mutating-requests-inflight),读400( –max-requests-inflight)。观察监控视图是否达到限速阈值(持续保持在固定值,视图为一条水平线)。如达到限速阈值,一般是客户端有大量异常请求/服务端响应慢,可结合apiserver qps监控和时延监控定位具体异常请求。集群较大的情况下,可确认下inflight限速是否合理(1000节点以下一般无需调整,大集群inflight调整为1000,3000一般是足够的)。
PromQL:
sum(apiserver_current_inflight_requests{cluster_id=~“xxx”}) by (requestKind,pod_name)
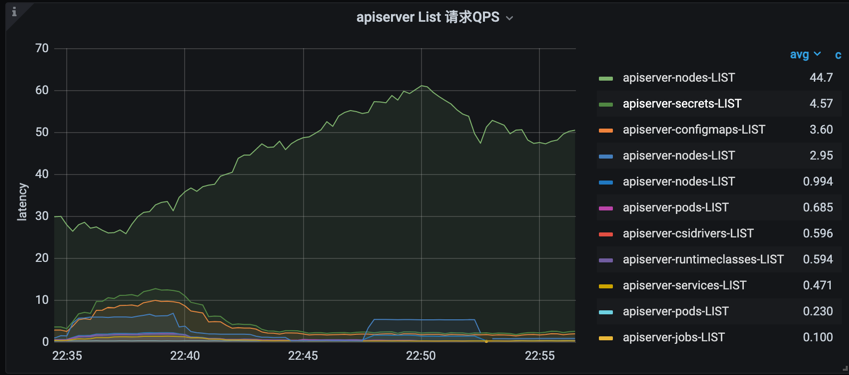
- List 请求 qps
PromQL:
topk(10, sum(rate(apiserver_request_count{cluster_id=“xxx”, verb=“LIST”}[5m])) by (component, client, resource,verb,scope)) or topk(10, sum(rate(apiserver_request_total{cluster_id=“xxx”, verb=“LIST”}[5m])) by (component, client, resource,verb,scope))
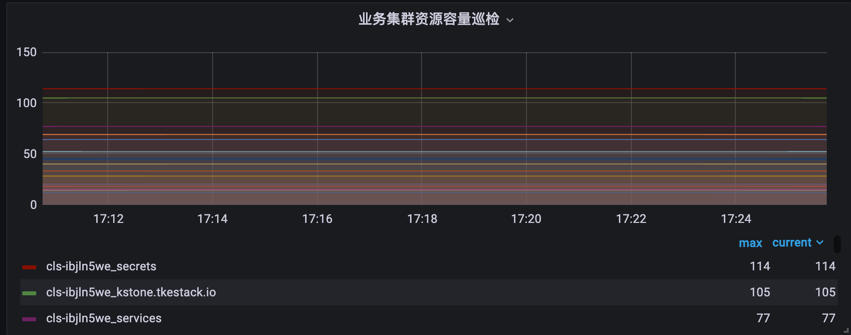
- 资源对象数量
PromQL:
topk(15, sum by (clusterId,etcdPrefix,resourceName) (kstone_monitor_etcd_key_total{clusterId=“xxx”}))
- apiserver 请求时延
PromQL:
sum(rate (apiserver_request_latencies_summary_sum{cluster_id=“xxx”, verb=~“GET|LIST|POST|PUT|DELETE|PATCH”}[5m])) by (resource, verb) / sum(rate (apiserver_request_latencies_summary_count{cluster_id=“xxx”, verb=~“GET|LIST|POST|PUT|DELETE|PATCH”}[5m])) by (resource, verb)/ 1000 / 300 > 0
avg(apiserver_request_duration_seconds_sum{cluster_id=“xxx”, verb=~“GET|LIST|POST|PUT|DELETE|PATCH”} / apiserver_request_duration_seconds_count{cluster_id=“xxx”, verb=~“GET|LIST|POST|PUT|DELETE|PATCH”}) by (resource, verb)
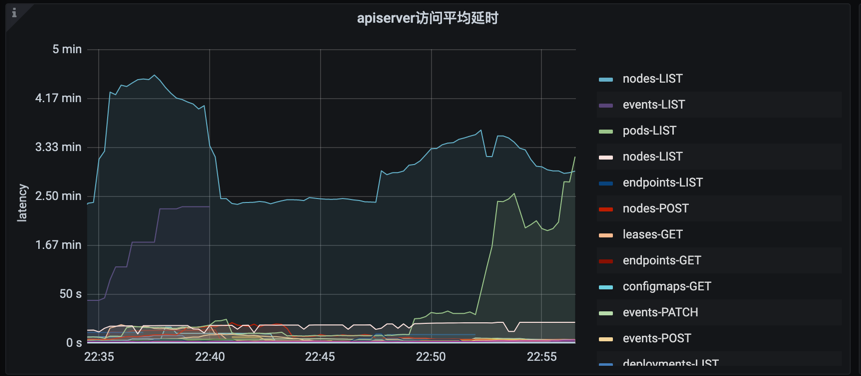
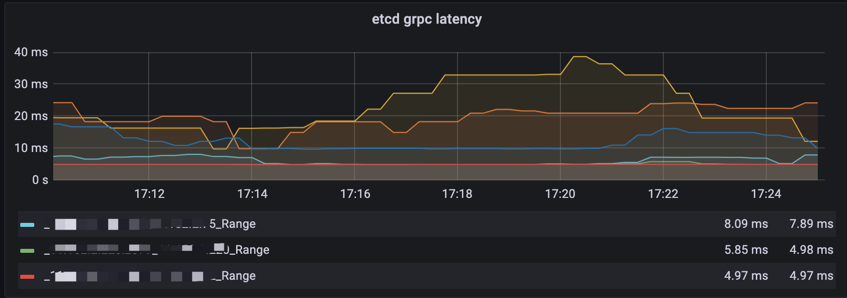
- etcd 请求时延,webhook 请求时延等
PromQL:
histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{cluster_id=“xxx”, grpc_method=~“Range|Txn”}[5m]) > 0) by (remark,instance,le,grpc_method,endpoint))
1.20 以上集群观察是否达到 APF 限速,主要观察请求等待时间和请求拒绝数量
PromQL:
请求并发限制:sum by (node, priority_level) apiserver_flowcontrol_request_concurrency_limit{cluster_id=“xxx”}
请求等待时间P99:histogram_quantile(0.99, sum by (flow_schema, priority_level, le) (apiserver_flowcontrol_request_wait_duration_seconds_bucket{cluster_id=“xxx”}))
请求执行时间P99:histogram_quantile(0.99, sum by (flow_schema, priority_level, le) (apiserver_flowcontrol_request_execution_seconds_bucket{cluster_id=“xxx”}))
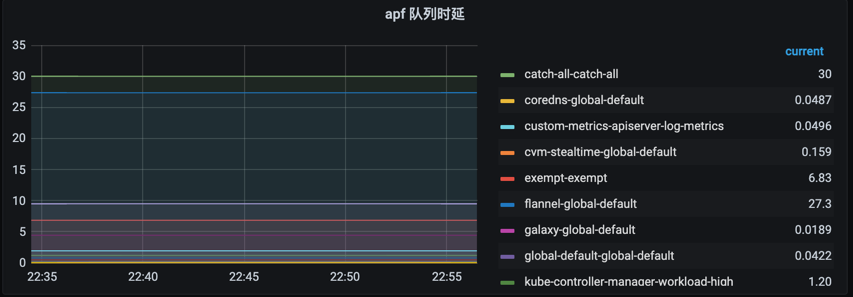
PromQL:
sum(apiserver_flowcontrol_rejected_requests_total{cluster_id=“xxx”})by (flow_schema)