1、问题描述
test-pod-hgfmk 命名空间下的 test-pod-hgfmk 这个 pod 处于 pending 状态,nominated node 是 132.10.134.193 节点
$ kubectl get po -n test-ns test-pod-hgfmk -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
test-pod-hgfmk 0/1 Pending 0 5m <none> <none> 132.10.134.193
describe pod 事件发现报 cpu、内存资源不足导致调度失败,但是监控发现集群中还有不少资源足够的节点
2、初步判断
怀疑是调度器内 node 缓存的资源信息和真实 node 可分配资源有差异导致,dump 出调度器节点缓存比对:
节点实际资源使用情况(kubectl describe node ):
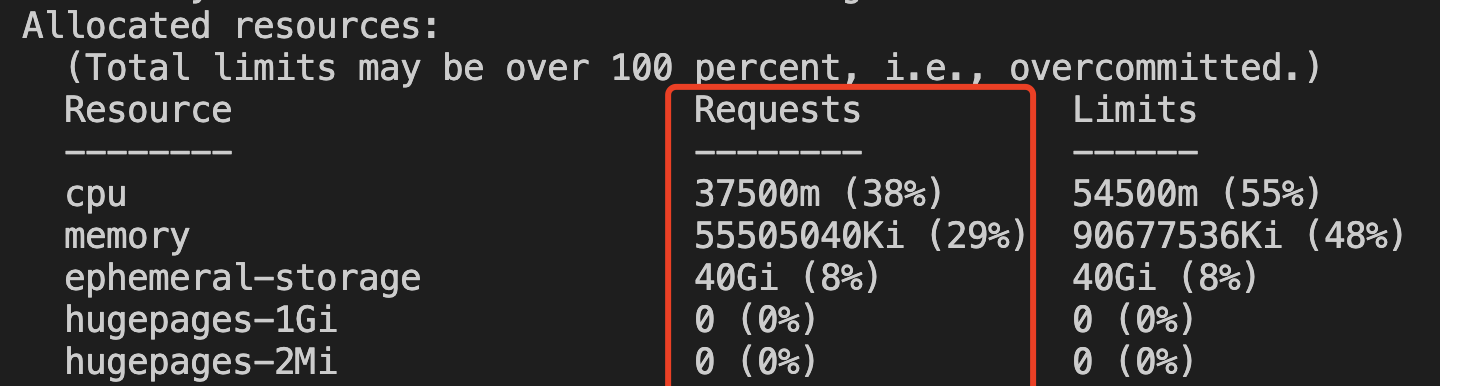
调度器当前缓存的节点资源信息(kill -SIGUSR2 ):
// 节点信息
{"log":"Node name: 132.10.134.193\n","stream":"stderr","time":"2021-10-16T08:06:42.929073912Z"}
// 节点requests信息(和上图相符)
{"log":"Requested Resources: {MilliCPU:37500 Memory:56837160960 EphemeralStorage:42949672960 AllowedPodNumber:0 ScalarResources:map[teg.tkex.oa.com/amd-cpu:36000 tke.cloud.tencent.com/eni-ip:1]}\n","stream":"stderr","time":"2021-10-16T08:06:42.929076647Z"}
// 节点 allocatable 信息(总可分配资源)
{"log":"Allocatable Resources:{MilliCPU:98667 Memory:191588200448 EphemeralStorage:482947890401 AllowedPodNumber:110 ScalarResources:map[hugepages-1Gi:0 hugepages-2Mi:0]}\n","stream":"stderr","time":"2021-10-16T08:06:42.929079502Z"}
// 节点 pod 信息
{"log":"Scheduled Pods(number: 3):\n","stream":"stderr","time":"2021-10-16T08:06:42.929085774Z"}
{"log":"name: ip-masq-agent-8v5lm, namespace: kube-system, uid: eee008d9-52ba-4c6d-ba7a-993a9c255718, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929102926Z"}
{"log":"name: kube-proxy-7sb7d, namespace: kube-system, uid: c53ef512-59f9-4afc-aa32-5f327b1e441d, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929105692Z"}
{"log":"name: node-exporter-p6rr4, namespace: kube-system, uid: dec7d32d-0652-430e-a013-ac40404a8428, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929122523Z"}
{"log":"Nominated Pods(number: 1):\n","stream":"stderr","time":"2021-10-16T08:06:42.929125529Z"}
// 该 pod 就是本次出现的 pending pod
{"log":"name: test-pod-hgfmk, namespace: test-ns, uid: ae6fea01-ba91-4a34-9c10-b57f04f2fbf7, phase: Pending, nominated node: 132.10.134.193\n","stream":"stderr","time":"2021-10-16T08:06:42.929128224Z"}
发现缓存信息和实际信息一致
3、构建测试 Pod 模拟调度过程
构建和业务request值、污点容忍条件一样的测试deployment,并通过 nodeSelector 指定上面出现的 nominated 节点调度:
cat << EOF > ./test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: test-schedule
name: test-schedule
spec:
replicas: 1
selector:
matchLabels:
app: test-schedule
template:
metadata:
labels:
app: test-schedule
spec:
nodeSelector:
kubernetes.io/hostname: 132.10.134.193
containers:
- image: mirrors.tencent.com/tkestack/nginx:1.7.9
name: test-schedule
resources:
limits:
cpu: "70"
memory: 100Gi
requests:
cpu: "53"
memory: 70Gi
tolerations:
- effect: NoSchedule
key: zone/ap-gz-3
operator: Exists
- effect: NoSchedule
key: zone/ap-gz-5
operator: Exists
- effect: NoSchedule
key: zone/ap-gz-6
operator: Exists
EOF
kubectl create -f test.yaml
发现使用和业务一样的 requests 值、污点却能够调度成功
3、原因分析
根据调度器源码分析,一个 Pod 出现 nominated node 的条件:
- 1、 当 Pod 通过 filter 调度算法后没有任何 Node 能够满足要求,且该 Pod 配置了 PriorityClass优先级(集群目前所有业务 Pod 优先级都默认为0)
- 2、 把集群所有 node 上比该 Pod 优先级低的 Pod 驱逐后,再让这个待调度的 Pod 走一遍 filter 调度算法,如果找到了任意一个满足要求的 Node,则认为该 Pod 可以参与抢占,并从这些满足要求的 Node 中随机选一个作为 nominated Node
然而查看这个 Pod nominatd 的节点,发现资源对业务 Pod 来说是完全够用的,说明这个 Pod 没办法通过第一轮正常调度时的 filter 算法,却能在抢占的阶段通过 filter 算法。理论上无论是正常调度时还是抢占时,用的都是同一套 filter 算法,为什么会出现两次跑 filter 算法结果不一致的情况呢? 区别在于正常调度时调用了 默认调度器的filter + 扩展调度器的filter ,而抢占时只调用了默认调度器的filter(没有配置扩展调度器抢占功能的前提下)
源码分析
我们看看调度器抢占的逻辑和 nominated node 产生的过程:
// pkg/scheduler/core/generic_scheduler.go
func (g *genericScheduler) Preempt(ctx context.Context, prof *profile.Profile, state *framework.CycleState, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
...
...
// 1、从缓存快照中获取集群所有节点信息
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
...
// 2、将集群所有健康节点作为备选的 nominated 节点
potentialNodes := nodesWherePreemptionMightHelp(allNodes, fitError)
...
// 3、从备选 nominated 节点中选出能够真正成为 nominated node 的节点
// 条件:去掉节点上所有比该 pod 低优先级的 pod 后,再跑一次 filter 调度算法后,集群中有满足条件的节点,则作为 nominated node
nodeToVictims, err := g.selectNodesForPreemption(ctx, prof, state, pod, potentialNodes, pdbs)
...
// 4、不仅需要走默认调度器的抢占逻辑,还有走扩展调度器的抢占逻辑,再过滤一批 nominated 节点
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
...
// 5、最终剩下的 nominated 节点随机选取一个作为 pod 的nominated node
candidateNode := pickOneNodeForPreemption(nodeToVictims)
...
return candidateNode, nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
上面流程中的3、4步就是产生 nominated node 的关键步骤:
- 第 3 步中,调度器会判断:如果把集群所有节点上比业务 Pod 优先级低的 Pod 驱逐后,该业务 Pod 能否通过调度器的 filter 调度算法(默认调度器),如果能通过则把这批通过 filter 算法的 node 作为 nominated node。 然而因为业务 Pod 的优先级都默认相等,所以并不会有低优先级的 Pod 需要驱逐,因此相当于集群不做改动重跑了一次 filter 算法,此时得到的节点就是资源充足且满足调度条件的一批节点(包含11.134.132.193)
- 第 4 步中,将第三步筛选出的 nominated node 放到扩展调度器中跑一次扩展调度器的抢占逻辑,再过滤掉一批不符合条件的 nominated node,剩下的才随机选择一个节点作为业务 Pod 最终的nominated node。
集群中配置了 scheduler extender 扩展调度器,其抢占逻辑:
// pkg/schedulerplugin/preempt.go
func (p *FloatingIPPlugin) Preempt(args *schedulerapi.ExtenderPreemptionArgs) map[string]*schedulerapi.MetaVictims {
fillNodeNameToMetaVictims(args)
// 1、解析 pod 的 ip 释放策略(永不释放IP、缩容时释放IP、不保留IP)
policy := parseReleasePolicy(&args.Pod.ObjectMeta)
// 2、如果 pod 的 ip 释放策略为不保留IP时,则不需要过滤 nominated 节点直接返回
if policy == constant.ReleasePolicyPodDelete {
return args.NodeNameToMetaVictims
}
// 3、获取业务 Pod 所属子网(因为固定ip策略,pod之前的ip所属子网保存在fip对象中)
subnetSet, err := p.getSubnet(args.Pod)
for nodeName := range args.NodeNameToMetaVictims {
node, err := p.NodeLister.Get(nodeName)
// 4、获取备选的 nominated node 的子网
subnet, err := p.getNodeSubnet(node)
if err != nil {
glog.Errorf("unable to get node %v subnet: %v", nodeName, err)
// 5、如果无法调 eni-provider 获取到 node 子网,滤掉这些节点
delete(args.NodeNameToMetaVictims, nodeName)
continue
}
// 6、如果 node 子网和 pod 原来的子网不匹配,也过滤掉这些节点
if !subnetSet.Has(subnet.String()) {
glog.V(4).Infof("remove node %v with subnet %v from victim", node.Name, subnet.String())
delete(args.NodeNameToMetaVictims, nodeName)
}
}
// 7、返回过滤后的 nominated 节点
return args.NodeNameToMetaVictims
}
调度流程分析
前面提到业务 Pod 没办法通过第一轮正常调度时的 filter 算法,却能在抢占的阶段通过 filter 算法,很可能是因为扩展调度器的抢占逻辑没有成功执行,nominated node没有被过滤掉,所以pod被设置了nominated node。该过程对应了下图中第4步,没有将和固定 IP Pod 不在一个子网的 nominated 节点过滤掉,直接把第3步产生的 nominated node (相当于只走了第1步的filter)作为 pod 的候选node,导致pod绑定了nominated node。
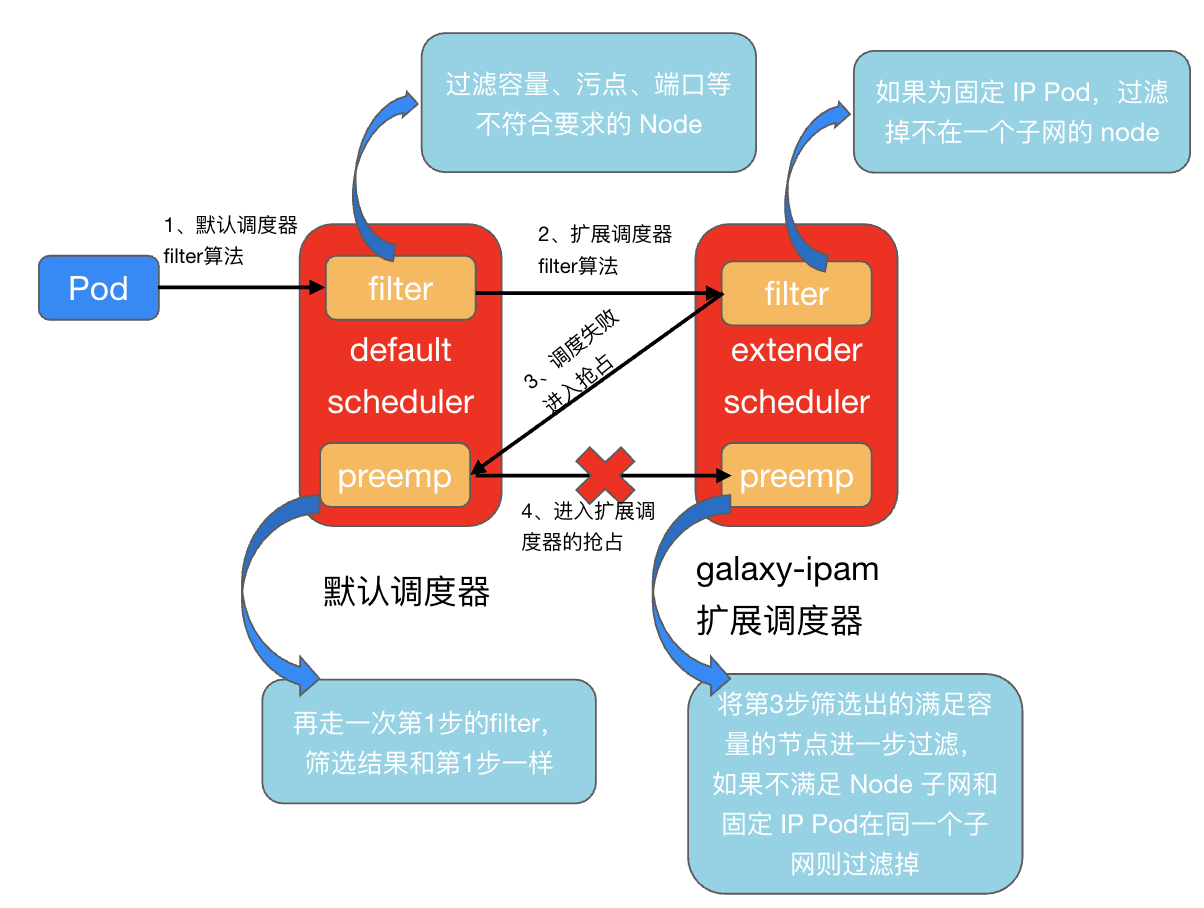
检查节点的调度器配置,确实缺少了扩展调度器的抢占配置:
$ cat /etc/kubernetes/schduler-config.json
{
"apiVersion": "kubescheduler.config.k8s.io/v1alpha2",
"kind": "KubeSchedulerConfiguration",
"leaderElection": {
"leaderElect": true
},
...
"extenders": [
{
"apiVersion": "v1beta1",
"enableHttps": false,
"filterVerb": "filter",
"BindVerb": "bind",
"weight": 1,
// 抢占配置
//"preemptVerb": "preempt",
"nodeCacheCapable": false,
"urlPrefix": "http://sheduler-extender:1003/v1",
}
]
}
下图是业务 pod 的调度全流程:
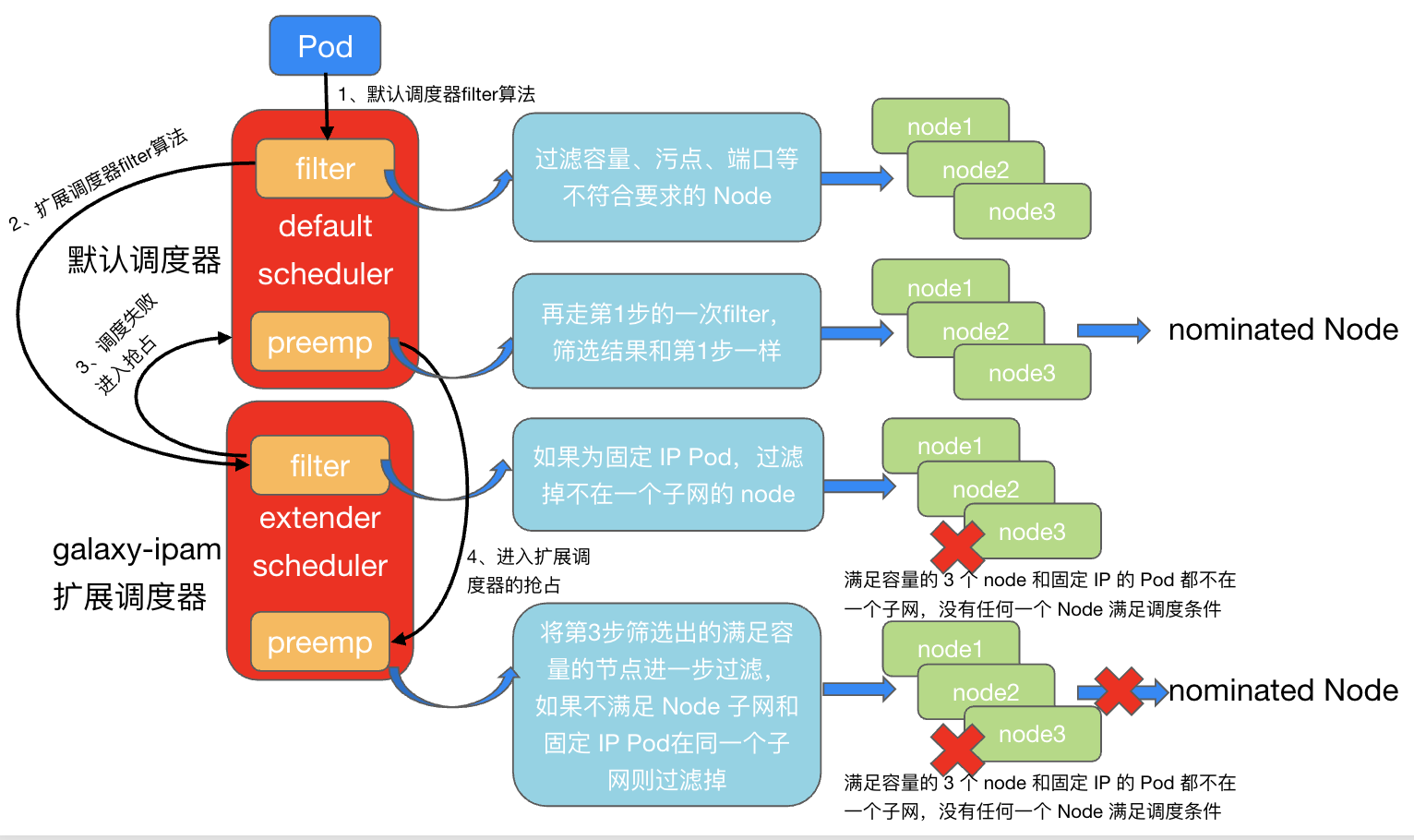
第一步:业务 Pod 进入默认调度器的 filter 算法,筛选出了符合容量、标签、污点的节点,此时,集群仅有的几个容量空闲的节点被筛选出来,进入下一步。
node1: 188.10.151.196
node2: 132.10.134.108
node3: 132.10.134.193
node4: 191.10.151.38
node5: 132.10.134.212
node6: 190.10.151.195
node7: 190.10.151.202
第二步:进入扩展调度器 sheduler-extender 的 filter 算法,因为该业务 Pod 的 IP 释放策略为缩容时释放,extender 为 Pod 保留了 IP,在 filter 算法中会依次判断第一步筛选出来的7个节点是否和业务 Pod 在同一个子网(只有在同一个子网的节点才能给 Pod 分配出上次固定的 IP),此时7个节点都不满足(满足同子网要求的节点容量不足,在第一步已经被过滤),调度失败,进入preemp抢占。 第三步:进入默认调度器的抢占,相当于重新走了一遍第一步的 filter,再次把满足容量、标签、污点的节点筛选出来,作为 nominated node 进入扩展调度器的抢占逻辑(如果没有配置扩展调度器的抢占逻辑,就会直接返回,给 pod 随机绑定一个 nominated node,这就是 nominated pod 出现的根本原因)
node1: 188.10.151.196
node2: 132.10.134.108
node3: 132.10.134.193
node4: 191.10.151.38
node5: 132.10.134.212
node6: 190.10.151.195
node7: 190.10.151.202
第四步:进入扩展调度器的抢占,把将第三步筛选出的满足容量、标签、污点的的节点进一步过滤,如果不满足 Node 子网和固定 IP Pod在同一个子网则过滤掉,最终所有 nominated node 都被过滤掉,不会产生 nominated 状态的 pending pod。 开启了扩展调度器的 preempt 抢占后,集群不再出现 nominated pod:
$ kubectl get po -n test-ns test-pod-bvtjg -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
test-pod-bvtjg 0/1 Pending 0 5m <none> <none> <none>
4、总结
- 一、 出现 nominated pod 的原因:调度器没有开启扩展调度器的抢占配置,导致满足 Pod 容量、标签、污点,但不满足和固定 IP Pod 在同一个子网的节点(nominated node)没有被过滤掉。
- 二、 出现 pending pod 的原因,并不是因为集群完全资源不足,而是部分业务开启了固定IP(缩容时释放)策略,导致 Pod 重建时,原节点资源被其它业务抢占,而满足资源的节点和 Pod 不在一个子网,导致调度失败。