一、优先级与抢占机制
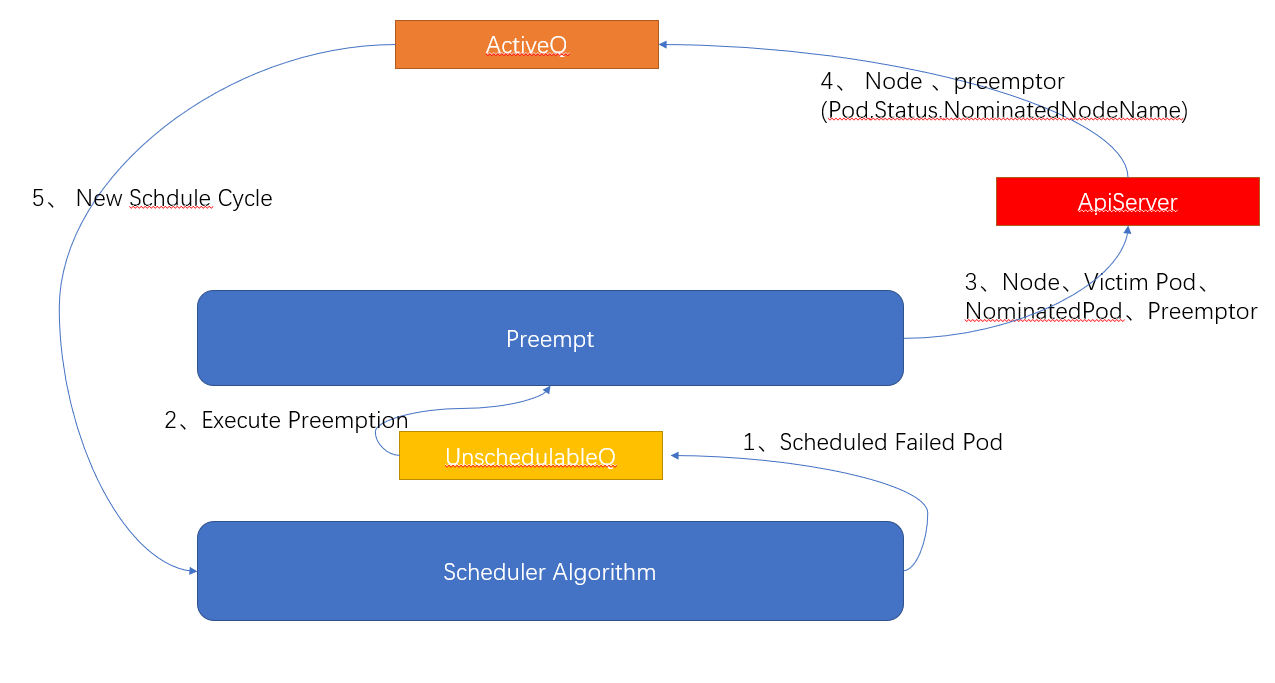
Kube-scheduler 在调度过程中,每次从调度队列(SchedulingQueue)中取出 Pod,进行一轮调度。那么调度队列中的 Pod 是按照什么顺序入队的呢?Pod 资源对象支持设置优先级(Priority)属性,通过优先级的不同,将优先级高的 Pod 放在调度队列的前面,优先进行调度。如果优先级高的 Pod 调度失败,没有找到合适的节点时,会放入无法调度队列(UnschedulableQueue)中,进入抢占阶段,在下次调度时将节点上优先级低的 Pod 驱逐。
 如何为 Pod 设置优先级呢?通过创建 PriorityClass 资源对象即可:
如何为 Pod 设置优先级呢?通过创建 PriorityClass 资源对象即可:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: ""
在 pod 中使用 PriorityClass :
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx-a
name: nginx-a
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx-a
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
memory: "64Mi"
cpu: 5
limits:
memory: "128Mi"
cpu: 5
priorityClassName: high-priority
Kubernetes 1.19 中使用了 Scheduling Framework,调度算法采用了插件的形式引入,例如调度开始前在对 Pod 进行优先级排列时,就使用了队列排序插件(QueueSortPlugin)
// pkg/scheduler/framework/v1alpha1/interface.go
type QueueSortPlugin interface {
Plugin
// Less are used to sort pods in the scheduling queue.
Less(*QueuedPodInfo, *QueuedPodInfo) bool
}
该插件需要实现排序的比较大小函数 Less(),官方的 Pod 优先级排序算法的 Less() 实现如下:
// pkg/scheduler/framework/plugins/queuesort/priority_sort.go
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
通过获取 Pod 的优先级(Priotrity)的值进行排序,大的排在前面,如果优先级一样大则根据创建时间比较,先创建的 Pod 排在前面。
二、亲和性调度
开发者对 Node 和 Pod 资源对象打上相应标签,调度器会通过标签对 Pod 进行亲和性(Affinity)和反亲和性(Anti-Affinity)调度。
- 节点亲和性(Node Affinity):表述 Pod 和 Node 的亲和关系,将 Pod 调度到特定的节点上
- Pod 亲和性(Pod Affinity):表述 Pod 和 Pod 之间的亲和关系,将一组业务紧密的 Pod 调度到同一个(组)节点上
- Pod 反亲和性(Pod Anti-Affinity):表述 Pod 和 Pod 之间的反亲和关系,尽量不将两个 Pod 调度到同一个(组)节点上
2.1 NodeAffinity
设置该特性能将 Pod 调度到特定的节点上,如让 IO 密集型 Pod 调度到 IO 设备配置高的机器上,CPU 密集型 Pod 调度到 CPU 核数高的机器上。 NodeAffinity 支持两种调度策略:
- RequiredDuringSchedulingIgnoredDuringExecution:强制要求 Pod 必须调度到满足亲和性的节点上,不满足条件则 Pod 调度失败并不断重试
- PreferredDuringSchedulingIgnoredDuringExecution:不强制要求 Pod 必须调度到满足亲和性的节点上,优先往满足亲和性的节点上调度,如果都不满足则选择其它较优节点
// vendor/k8s.io/api/core/v1/types.go
type NodeAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution *NodeSelector `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,opt,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []PreferredSchedulingTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
2.2 PodAffinity
设置该特性能将 Pod 调度到另一个 Pod 所在的同一个(或有同样亲和性)的节点上,主要为了缩短两个业务紧密的 Pod 的网络传输延迟,加快网络传输效率。 和 NodeAffinity 类似,PodAffinity 也支持两种调度策略:
- RequiredDuringSchedulingIgnoredDuringExecution:强制要求 Pod 必须调度到满足和其它 Pod 亲和性(和其它 Pod 相邻或相同)的节点上,不满足条件则 Pod 调度失败并不断重试
- PreferredDuringSchedulingIgnoredDuringExecution:不强制要求 Pod 必须调度到满足和其它 Pod 亲和性(和其它 Pod 相邻或相同)的节点上,优先往满足亲和性的节点上调度,如果都不满足则选择其它较优节点
// vendor/k8s.io/api/core/v1/types.go
type PodAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution []PodAffinityTerm `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,rep,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []WeightedPodAffinityTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
2.3 PodAntiAffinity
设置该特性能将 Pod 调度到另一个 Pod 所在的不同的节点上,主要为了实现 Pod 的高可用和降低节点故障带来的风险。 和 NodeAffinity、PodAffinity 类似,PodAntiAffinity 也支持两种调度策略:
- RequiredDuringSchedulingIgnoredDuringExecution:强制要求 Pod 必须不能调度到和其它 Pod 相斥的节点上,不满足条件则 Pod 调度失败并不断重试
- PreferredDuringSchedulingIgnoredDuringExecution:不强制要求 Pod 必须不能调度到和其它 Pod 相斥的节点上,优先往满足条件的节点上调度,如果都不满足则选择其它较优节点
// vendor/k8s.io/api/core/v1/types.go
type PodAntiAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution []PodAffinityTerm `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,rep,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []WeightedPodAffinityTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
三、内置调度算法
Kubernetes 1.19 版本中引入了调度器框架(Scheduler Framework),将内置调度算法以插件的形式配置和运行。相比于旧版本的调度策略,其核心内容没有变化,仍然是采用了两大核心的调度算法:
- 基于谓词的预选算法(Predicate):检查待调度的 Pod 是否能够调度到待选节点中,如因为节点的磁盘、内存、CPU、标签、端口等硬性条件不符合该 Pod 的运行条件,直接将该节点过滤,不参与后续的调度流程。
- 基于优先级的优选算法(Priority):为每一个可调度的节点根据各项指标进行打分,选出分数最高的节点做为最优节点进行 Pod 的调度。
在 1.19 的源码中,pkg/scheduler/framework/plugins 目录下为 Kubernetes 的调度器内置调度算法的各种实现:
 不同算法可能使用了多个调度插件,调度插件主要有11种:
不同算法可能使用了多个调度插件,调度插件主要有11种:
- Queue sort 对待调度的Pod进行排序(默认根据 Pod 的 Priority 值排序)
- PreFilter Pod调度前的条件检查,如果检查不通过,直接结束本调度周期(如:过滤带有某些标签、annotation的pod)
- Filter 过滤掉不符合当前Pod运行条件的 Node(相当于旧版调度器中的 Predicate)
- PostFilter Filter插件执行完后执行,一般用于 Pod 抢占调度
- PreScore 节点打分前进行相关操作
- Scoring 对节点进行打分(相当于旧版调度器中的 Priority) 打分完成后对分数进行规整,将分数变换到一个统一的范围中(normalize) ((nodeScore.Score - lowest) * newRange / oldRange) + framework.MinNodeScore ((当前分数-最低分数)*调度器默认分数范围和实际分数范围的比例)+调度器默认最低分数
- Reserve
- Permit Pod绑定之前的准入控制 – approve – deny – wait (带超时时间)
- PreBind 绑定Pod之前的逻辑,如:先预挂载共享存储,查看是否正常挂载
- Bind
- PostBind Pod绑定成功后的资源清理逻辑
无论是内置调度算法还是自定义的扩展调度算法,都要在官方提供的这11个插件接口上做扩展,如内置的 NodeName 调度算法,其功能是过滤掉 Pod 中除了 nodeName 字段设置的节点之外的其它节点,需要用到 Filter 插件执行 Predicate 算法:
// pkg/scheduler/framework/interface.go
// Filter 插件的接口,任何使用该插件的调度器都需要实现自己的 Filter 方法来定义 Node 的过滤规则
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
以下为内置预选算法 NodeName 对 Filter 插件的实现:
// pkg/scheduler/framework/plugins/nodename/node_name.go
// 定义名为 NodeName 调度器插件结构体
type NodeName struct{}
// NodeName 调度器插件为 FilterPlugin 类型,需要实现 FilterPlugin 接口的方法
var _ framework.FilterPlugin = &NodeName{}
// Filter 方法即为 FilterPlugin 接口的实现方法
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo.Node() == nil {
return framework.NewStatus(framework.Error, "node not found")
}
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}
// 该调度器的核心逻辑,如果 Pod 的 NodeName 字段不匹配待调度的节点名,则过滤掉
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) bool {
return len(pod.Spec.NodeName) == 0 || pod.Spec.NodeName == nodeInfo.Node().Name
}
// 初始化调度器插件
func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &NodeName{}, nil
}
四、对调度器扩展机制的思考
在 1.19 版本中,当我们需要自定义扩展调度器时,使用和官方内置调度算法一样的套路,实现官方提供的插件接口即可。 我们知道旧版本的扩展调度器(Scheduler Extender)基于外部 Webhook 服务,自定义的扩展调度算法需要在官方调度算法执行完后再通过 HTTP 请求的方式访问我们自定义的扩展调度器,这种扩展方式会存在不少问题:
- 调度算法执行时机不灵活 扩展的predicate、priority算法只能在默认调度器的调度算法后执行
- 序列化、反序列化慢 扩展调度器使用HTTP+JSON的形式序列化、反序列化
- 调用扩展调度器异常后当前Pod的调度任务直接被丢弃 需要一种通知机制来让scheduler感知到扩展调度器异常
- 无法共享默认调度器的缓存(因为扩展调度器和默认调度器在不同的进程)
而新版本的调度器基于调度器框架,以插件的形式进行扩展,可以在调度的任何一个环境扩展我们自己的调度逻辑,非常灵活,而且扩展的调度器逻辑和官方的调度器服务的代码是相互耦合的,跑在同一个进程中,避免了网络通信带来的不稳定性和不必要的开销,是目前乃至未来调度器扩展方式的主流方案,而基于外部服务的扩展调度器机制将会慢慢退出官方调度器的舞台。