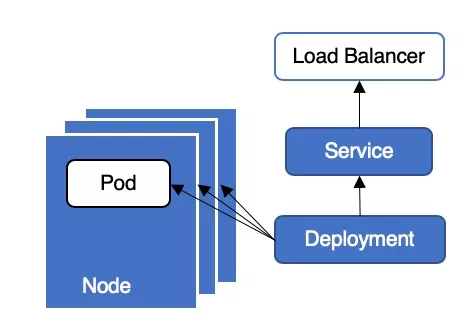
Kubernetes 集群中,业务通常采用 Deployment + LoadBalancer 类型 Service 的方式对外提供服务,其典型部署架构如图 1 所示。这种架构部署和运维都十分简单方便,但是在应用更新或者升级时可能会存在服务中断,引发线上问题。今天我们来详细分析下这种架构为何在更新应用时会发生服务中断以及如何避免服务中断。
为何会发生服务中断?
Deployment 滚动更新时会先创建新 pod,等待新 pod running 后再删除旧 pod。
1. 新建 Pod
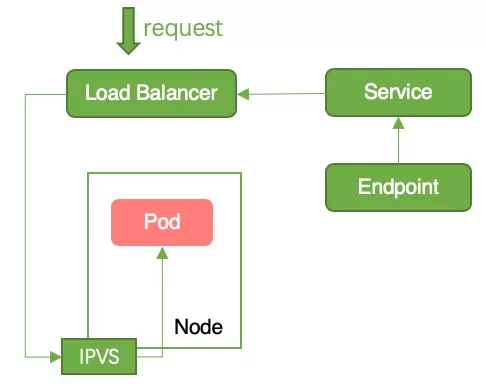
中断原因:Pod running 后被加入到 Endpoint 后端,容器服务监控到 Endpoint 变更后将 Node 加入到 LB 后端。此时请求从 LB 转发到 Pod 中,但是 Pod 业务代码还未初始化完毕,无法处理请求,导致服务中断,如图 2 所示。
解决方法:为 pod 配置就绪检测,等待业务代码初始化完毕后后再将 node 加入到 LB 后端。
2. 删除 Pod
在删除旧 pod 过程中需要对多个对象(如 Endpoint、ipvs/iptables、LB)进行状态同步,并且这些同步操作是异步执行的,整体同步流程如图 3 所示。
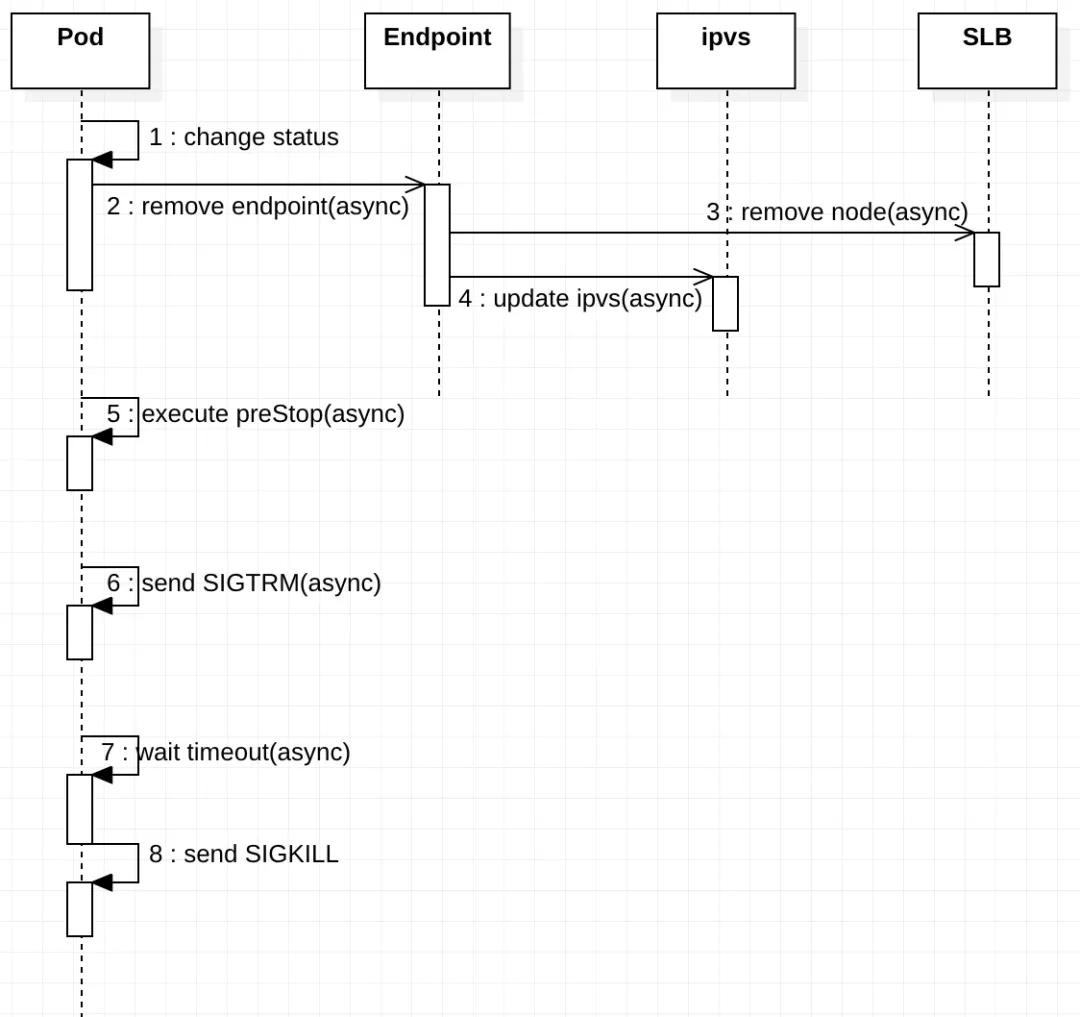
Pod 删除过程
pod 状态变更:将 Pod 设置为 Terminating 状态,并从所有 Service 的 Endpoints 列表中删除。此时,Pod 停止获得新的流量,但在 Pod 中运行的容器不会受到影响;
执行 preStop Hook:Pod 删除时会触发 preStop Hook,preStop Hook 支持 bash 脚本、TCP 或 HTTP 请求;
发送 SIGTERM 信号:向 Pod 中的容器发送 SIGTERM 信号;
等待指定的时间:terminationGracePeriodSeconds 字段用于控制等待时间,默认值为 30 秒。该步骤与 preStop Hook 同时执行,因此 terminationGracePeriodSeconds 需要大于 preStop 的时间,否则会出现 preStop 未执行完毕,pod 就被 kill 的情况;
发送 SIGKILL 信号:等待指定时间后,向 pod 中的容器发送 SIGKILL 信号,删除 pod。
Endpoints 删除不及时
中断原因:上述 1、2、3、4 步骤同时进行,因此有可能存在 Pod 收到 SIGTERM 信号并且停止工作后,还未从 Endpoints 中移除的情况。此时,请求从 lb 转发到 pod 中,而 Pod 已经停止工作,因此会出现服务中断,如图 4 所示。
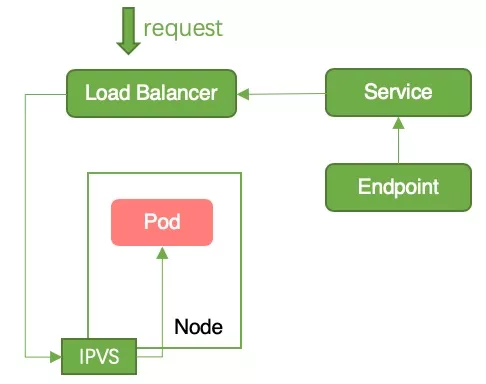
解决方法:为 pod 配置 preStop Hook,使 Pod 收到 SIGTERM 时 sleep 一段时间而不是立刻停止工作,从而确保从 LB 转发的流量还可以继续被 Pod 处理。
iptables/ipvs 规则删除不及时
中断原因:当 pod 变为 termintaing 状态时,会从所有 service 的 endpoint 中移除该 pod。kube-proxy 会清理对应的 iptables/ipvs 条目。而容器服务 watch 到 endpoint 变化后,会调用 lb openapi 移除后端,此操作会耗费几秒。由于这两个操作是同时进行,因此有可能存在节点上的 iptables/ipvs 条目已经被清理,但是节点还未从 lb 移除的情况。此时,流量从 lb 流入,而节点上已经没有对应的 iptables/ipvs 规则导致服务中断,如图 5 所示。
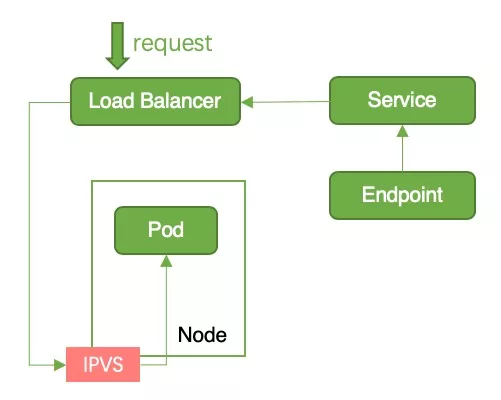 解决方法如下:
解决方法如下:
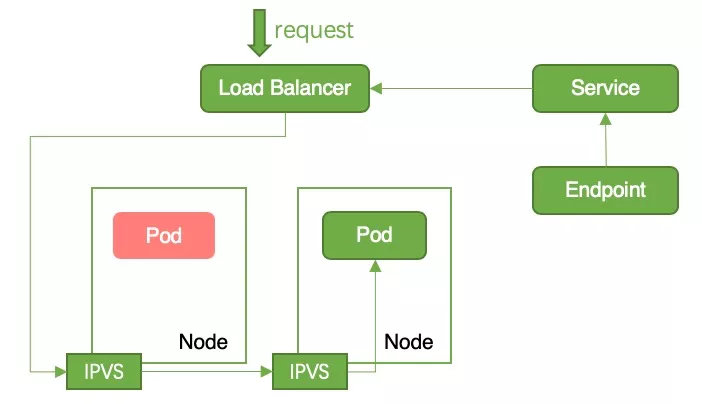
Cluster 模式:Cluster 模式下 kube-proxy 会把所有业务 Pod 写入 Node 的 iptables/ipvs 中,如果当前 Node 没有业务 pod,则该请求会被转发给其他 Node,因此不会存在服务中断,如 6 所示;
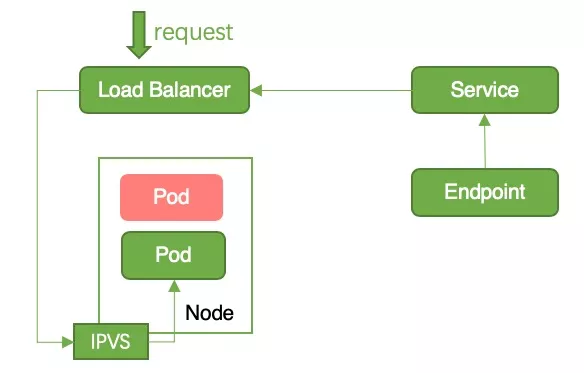
Local 模式:Local 模式下,kube-proxy 仅会把 Node 上的 pod 写入 iptables/ipvs。当 Node 上只有一个 pod 且状态变为 terminating 时,iptables/ipvs 会将该 pod 记录移除。此时请求转发到这个 node 时,无对应的 iptables/ipvs 记录,导致请求失败。这个问题可以通过原地升级来避免,即保证更新过程中 Node 上至少有一个 Running Pod。原地升级可以保障 Node 的 iptables/ipvs 中总会有一条业务 pod 记录,因此不会产生服务中断,如图 7 所示;
如何避免服务中断?
避免服务中断可以从 Pod 和 Service 两类资源入手,接下来将针对上述中断原因介绍相应的配置方法。
1. Pod 配置
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: default
spec:
containers:
- name: nginx
image: nginx
# 存活检测
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 就绪检测
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 优雅退出
lifecycle:
preStop:
exec:
command:
- sleep
- 30
terminationGracePeriodSeconds: 60
注意:需要合理设置就绪检测(readinessProbe)的探测频率、延时时间、不健康阈值等数据,部分应用启动时间本身较长,如果设置的时间过短,会导致 POD 反复重启。
livenessProbe 为存活检测,如果失败次数到达阈值(failureThreshold)后,pod 会重启,具体配置见官方文档;
readinessProbe 为就绪检查,只有就绪检查通过后,pod 才会被加入到 Endpoint 中。容器服务监控到 Endpoint 变化后才会将 node 挂载到 lb 后端;
preStop 时间建议设置为业务处理完所有剩余请求所需的时间,terminationGracePeriodSeconds 时间建议设置为 preStop 的时间再加30秒以上。
2. Service 配置
Cluster 模式(externalTrafficPolicy: Cluster)
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
spec:
externalTrafficPolicy: Cluster
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
容器服务会将集群中所有节点挂载到 LB 的后端(使用 BackendLabel 标签配置后端的除外),因此会快速消耗 LB quota。LB 限制了每个 ECS 上能够挂载的 LB 的个数,默认值为 50,当 quota 消耗完后会导致无法创建新的监听及 LB。
Cluster 模式下,如果当前节点没有业务 pod 会将请求转发给其他 Node。在跨节点转发时需要做 NAT,因此会丢失源 IP。
Local 模式(externalTrafficPolicy: Local)
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
spec:
externalTrafficPolicy: Local
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
- 需要尽可能的让每个节点在更新的过程中有至少一个的Running的Pod
- 通过修改UpdateStrategy和利用nodeAffinity尽可能的保证在原地rolling update
- UpdateStrategy可以设置Max Unavailable为0,保证有新的Pod启动后才停止之前的pod
- 先对固定的几个节点打上label用来调度
- 使用nodeAffinity+和超过相关node数量的replicas数量保证尽可能在原地建新的Pod 例如:
apiVersion: apps/v1
kind: Deployment
......
strategy:
rollingUpdate:
maxSurge: 50%
maxUnavailable: 0%
type: RollingUpdate
......
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: deploy
operator: In
values:
- nginx
容器服务默认会将 Service 对应的 Pod 所在的节点加入到 LB 后端,因此 LB quota 消耗较慢。Local 模式下请求直接转发到 pod 所在 node,不存在跨节点转发,因此可以保留源 IP 地址。Local 模式下可以通过原地升级的方式避免服务中断,yaml 文件如上。
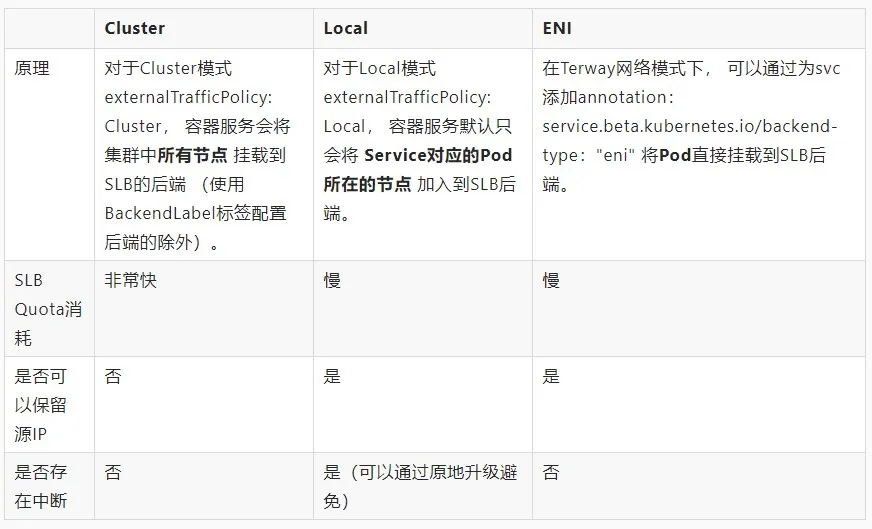
三种 svc 模式对比如下图所示:
3. 结论
如果集群中 lb 数量不多且不需要保留源 ip:选用 cluster 模式 + 设定 Pod 优雅终止 + 就绪检测;
如果集群中 lb 数量较多或需要保留源 ip:选用 local 模式 + 设定 Pod 优雅终止 + 就绪检测 + 原地升级(保证更新过程中每个节点上至少有一个 Running Pod)。