一、为什么需要抢占机制
当一个 pod 调度失败后,暂时处于 pending 状态,直到 pod 被更新或者集群状态发生变化,调度器才会对这个 pod 进行重新调度。但在实际的业务场景中会存在在线与离线业务之分,若在线业务的 pod 因资源不足而调度失败时,此时就需要离线业务下掉一部分为在线业务提供资源,即在线业务要抢占离线业务的资源,此时就需要 scheduler 的优先级和抢占机制了,该机制解决的是 pod 调度失败时该怎么办的问题,若该 pod 的优先级比较高此时并不会被”搁置”,而是会”挤走”某个 node 上的一些低优先级的 pod,这样就可以保证高优先级的 pod 调度成功。
二、如何使用抢占机制
1、创建 PriorityClass 对象:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: ""
2、在 deployment、statefulset 或者 pod 中声明使用已有的 priorityClass 对象即可
在 pod 中使用:
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx-a
name: nginx-a
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx-a
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
memory: "64Mi"
cpu: 5
limits:
memory: "128Mi"
cpu: 5
priorityClassName: high-priority
在 deployment 中使用:
template:
spec:
containers:
- image: nginx
name: nginx-deployment
priorityClassName: high-priority
三、相关流程
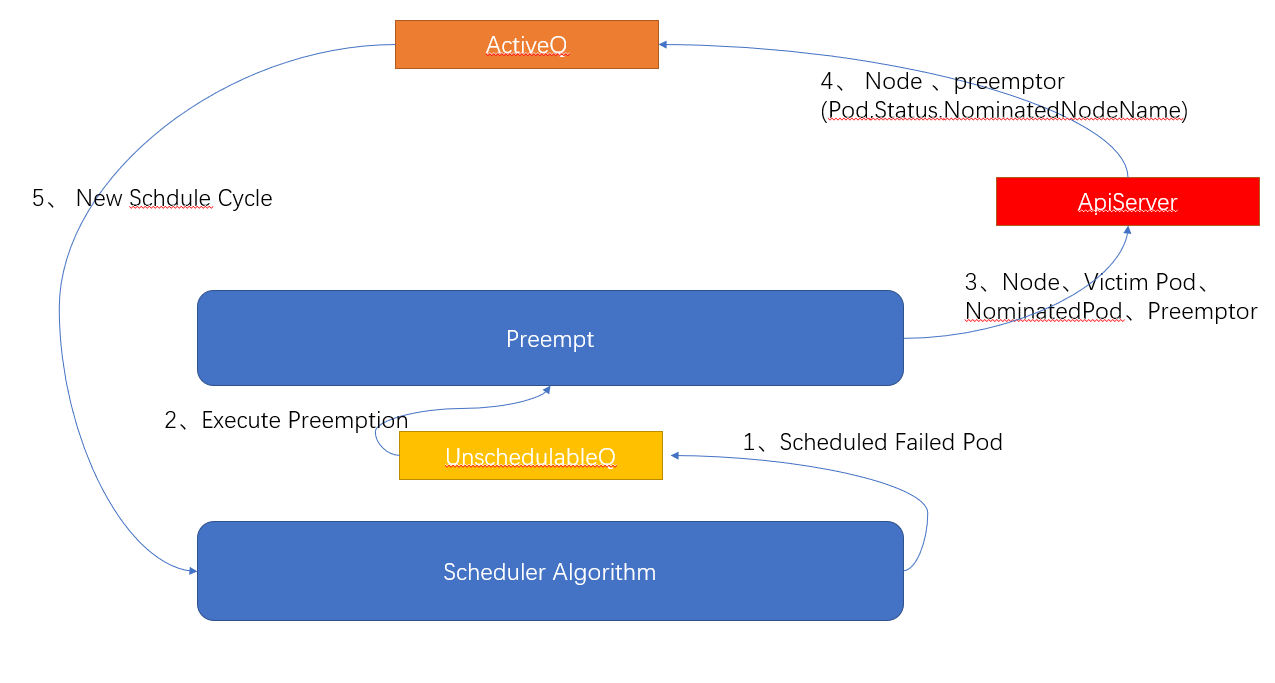 1、将调度失败的Pod放入UnscheduleableQ队列中
2、如果开启了抢占,则执行抢占算法Preempt
3、抢占算法Preempt返回抢占成功的 node、要删除的 pods(victims) 、被抢占的Pod(NominatedPod)和抢占者Pod(Preemptor)。将抢占者Pod的 pod.Status.NominatedNodeName字段设置为抢占成功的node名字,提交给ApiServer。并在该节点移除优先级低的被抢占的 pods(victims)。同时清除NominatedPod的pod.Status.NominatedNodeName字段,也提交给ApiServer。最后将**抢占者Pod(Preemptor)**放入AcitiveQ中,等待下次调度。
1、将调度失败的Pod放入UnscheduleableQ队列中
2、如果开启了抢占,则执行抢占算法Preempt
3、抢占算法Preempt返回抢占成功的 node、要删除的 pods(victims) 、被抢占的Pod(NominatedPod)和抢占者Pod(Preemptor)。将抢占者Pod的 pod.Status.NominatedNodeName字段设置为抢占成功的node名字,提交给ApiServer。并在该节点移除优先级低的被抢占的 pods(victims)。同时清除NominatedPod的pod.Status.NominatedNodeName字段,也提交给ApiServer。最后将**抢占者Pod(Preemptor)**放入AcitiveQ中,等待下次调度。
//k8s.io/kubernetes/pkg/scheduler/scheduler.go:352
func (sched *Scheduler) preempt(pluginContext *framework.PluginContext, fwk framework.Framework, preemptor *v1.Pod, scheduleErr error) (string, error) {
// 获取 pod info
preemptor, err := sched.PodPreemptor.GetUpdatedPod(preemptor)
if err != nil {
klog.Errorf("Error getting the updated preemptor pod object: %v", err)
return "", err
}
// 执行抢占算法
node, victims, nominatedPodsToClear, err := sched.Algorithm.Preempt(pluginContext, preemptor, scheduleErr)
if err != nil {
......
}
var nodeName = ""
if node != nil {
nodeName = node.Name
// 更新 scheduler 缓存,为抢占者绑定 nodename,即设定 pod.Status.NominatedNodeName
sched.SchedulingQueue.UpdateNominatedPodForNode(preemptor, nodeName)
// 将 pod info 提交到 apiserver
err = sched.PodPreemptor.SetNominatedNodeName(preemptor, nodeName)
if err != nil {
sched.SchedulingQueue.DeleteNominatedPodIfExists(preemptor)
return "", err
}
// 删除被抢占的 pods
for _, victim := range victims {
if err := sched.PodPreemptor.DeletePod(victim); err != nil {
return "", err
}
......
}
}
// 删除被抢占 pods 的 NominatedNodeName 字段
for _, p := range nominatedPodsToClear {
rErr := sched.PodPreemptor.RemoveNominatedNodeName(p)
if rErr != nil {
......
}
}
return nodeName, err
}
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:320
func (g *genericScheduler) Preempt(pluginContext *framework.PluginContext, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
fitError, ok := scheduleErr.(*FitError)
if !ok || fitError == nil {
return nil, nil, nil, nil
}
// 判断 pod 是否支持抢占,若 pod 已经抢占了低优先级的 pod,被抢占的 pod 处于 terminating 状态中,则不会继续进行抢占
if !podEligibleToPreemptOthers(pod, g.nodeInfoSnapshot.NodeInfoMap, g.enableNonPreempting) {
return nil, nil, nil, nil
}
// 从缓存中获取 node list
allNodes := g.cache.ListNodes()
if len(allNodes) == 0 {
return nil, nil, nil, ErrNoNodesAvailable
}
// 过滤 predicates 算法执行失败的 node 作为抢占的候选 node
potentialNodes := nodesWherePreemptionMightHelp(allNodes, fitError)
// 如果过滤出的候选 node 为空则返回抢占者作为 nominatedPodsToClear
if len(potentialNodes) == 0 {
return nil, nil, []*v1.Pod{pod}, nil
}
// 获取 PodDisruptionBudget objects
pdbs, err := g.pdbLister.List(labels.Everything())
if err != nil {
return nil, nil, nil, err
}
// 过滤出可以抢占的 node 列表
nodeToVictims, err := g.selectNodesForPreemption(pluginContext, pod, g.nodeInfoSnapshot.NodeInfoMap, potentialNodes, g.predicates,
g.predicateMetaProducer, g.schedulingQueue, pdbs)
if err != nil {
return nil, nil, nil, err
}
// 若有 extender 则执行
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
if err != nil {
return nil, nil, nil, err
}
// 选出最佳的 node
candidateNode := pickOneNodeForPreemption(nodeToVictims)
if candidateNode == nil {
return nil, nil, nil, nil
}
// 移除低优先级 pod 的 Nominated,更新这些 pod,移动到 activeQ 队列中,让调度器
// 为这些 pod 重新 bind node
nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name)
if nodeInfo, ok := g.nodeInfoSnapshot.NodeInfoMap[candidateNode.Name]; ok {
return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
return nil, nil, nil, fmt.Errorf(
"preemption failed: the target node %s has been deleted from scheduler cache",
candidateNode.Name)
}
4、在下一个调度周期,kube-scheduler从ActiveQ中获取到抢占者Pod重新执行调度。