Scheduler工作流程
我们在使用K8S集群时,常常需要对Deployment Controller做创建、修改、删除操作,K8S对应的会创建、销毁和重新调度Pod在合适的节点上,这个调度过程是通过K8S的Scheduler调度器实现的。Schduler的工作流程如下图所示:
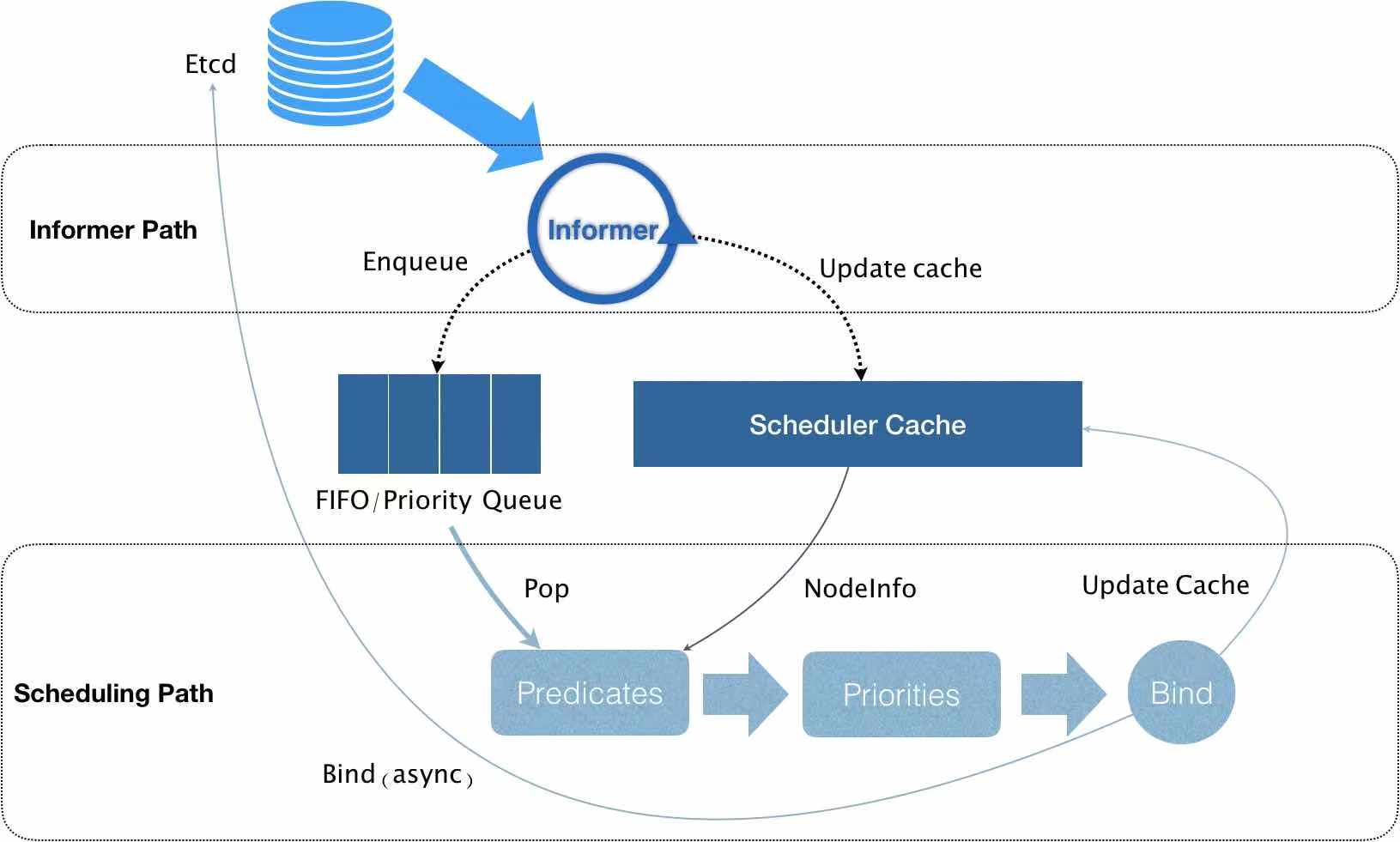 Informer组件一直在监听etcd中Pod信息的变化,准确来说,监听的是Pod信息中Spec.nodeName字段的变化,一旦检测到该字段为空,则认为集群中有Pod尚未调度到Node中,这时Informer开始将这个Pod的信息加入队列中,同时更新Scheduler Cache缓存。接下来Pod信息从队列中出队,进入Predicates(预选阶段),该阶段通过一系列的预选算法选出集群中适合Pod运行的节点,带着这些信息进入Priorities(优选阶段)。同理,该阶段通过一系列的优选算法为适合该Pod调度对每个Node进行打分,最后选出集群中最适合(也就是分数最高的)Pod运行的一个节点,最后将这个节点和Pod进行绑定(Bind),更新缓存,从而实现Pod的调度。
Informer组件一直在监听etcd中Pod信息的变化,准确来说,监听的是Pod信息中Spec.nodeName字段的变化,一旦检测到该字段为空,则认为集群中有Pod尚未调度到Node中,这时Informer开始将这个Pod的信息加入队列中,同时更新Scheduler Cache缓存。接下来Pod信息从队列中出队,进入Predicates(预选阶段),该阶段通过一系列的预选算法选出集群中适合Pod运行的节点,带着这些信息进入Priorities(优选阶段)。同理,该阶段通过一系列的优选算法为适合该Pod调度对每个Node进行打分,最后选出集群中最适合(也就是分数最高的)Pod运行的一个节点,最后将这个节点和Pod进行绑定(Bind),更新缓存,从而实现Pod的调度。
Priority优选流程
整个优选流程如下图:
将需要调度的Pod列表和Node列表传入各种优选算法进行打分,最终整合成结果集HostPriorityList:
type HostPriority struct {
Host string
Score int
}
type HostPriorityList []HostPriority
这个HostPriorityList数组保存了每个Node的名字和它对应的分数,最后选出分数最高的Node对Pod进行绑定和调度。 那么优选算法具体是怎样工作的呢?我们来看看源码中的优选算法结构体PriorityConfig:
type PriorityConfig struct {
Name string
Map PriorityMapFunction
Reduce PriorityReduceFunction
// TODO: Remove it after migrating all functions to
// Map-Reduce pattern.
Function PriorityFunction
Weight int
}
优选算法由一系列的PriorityConfig(也就是PriorityConfig数组)组成,每个Config代表了一个算法,Config描述了名字Name、权重Weight、Function(一种优选算法函数类型)、Map-Reduce(Map和Reduce成对出现,是另一种优选算法函数类型)。需要调度的Pod分别对每个合适的Node(N)执行每个优选算法(A)进行打分,最后得到一个二维数组,元素分别为A1N1,A1N2,A1N3… ,行代表一个算法对应不同的Node计算得到的分值,列代表同一个Node对应不同算法的分值:
| N1 | N2 | N3 | |
|---|---|---|---|
| A1 | { Name:“node1”,Score:5,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:3,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:1,PriorityConfig:{…weight:1}} |
| A2 | { Name:“node1”,Score:6,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:2,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:3,PriorityConfig:{…weight:1}} |
| A3 | { Name:“node1”,Score:4,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:7,PriorityConfig:{..weight:1.}} | { Name:“node3”,Score:2,PriorityConfig:{…weight:1}} |
最后将结果合并(Combine)成一维数组HostPriorityList :
HostPriorityList =[{ Name:"node1",Score:15},{ Name:"node2",Score:12},{ Name:"node3",Score:6}]
这样就完成了对每个Node进行优选算法打分的流程
Fucntion类型优选算法
具体的优选算法分为两种,先介绍第一种PriorityFunction类型的优选算法。
type PriorityFunction func(pod *v1.Pod, nodeNameToInfo map[string]*schedulercache.NodeInfo, nodes []*v1.Node) (schedulerapi.HostPriorityList, error) {
...
...省略其它逻辑
...
//轮询每一个优选算法struct
for i := range priorityConfigs {
// 如果第i个priorityConfigs配置了PriorityFunction,则调用;
if priorityConfigs[i].Function != nil {
wg.Add(1)
// 这里index就是i,表示开始调用第i个算法,得到的结果放在第i个result的结果集里
go func(index int) {
defer wg.Done()
var err error
// 所以这里的results[index]就好理解了;后面priorityConfigs[index]的索引也是index,
// 这里表达的是第N个优选配置里有PriorityFunction,那么这个Function的计算结果保存在
// results的第N个格子里;
// 这里开始调用PriorityFunction类型的优选算法
results[index], err = priorityConfigs[index].Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i)
} else {
// 如果没有定义Function,也就是使用了Map-Reduce方式的,这里在下一小节详细说明;
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
...
}
}
...
...省略其它逻辑
...
}
Map-Reduce类型优选算法
第二种算法类型是PriorityMapFunction和PriorityReduceFunction,它们成对出现,先通过Map函数进行并行计算,再通过Reduce函数将计算结果进行统计。
// ParallelizeUntil是client-go的并发工具包,这里表示最多开启16个线程处理nodes个数的任务,重点关注最后一个参数,这是一个匿名函数;
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
// 这里的index是[0,len(nodes)-1],相当于遍历所有的nodes;
nodeInfo := nodeNameToInfo[nodes[index].Name]
// 这个for循环遍历的是所有的优选配置,如果是Function类型就跳过,新逻辑就继续;
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
// 因为前面Fucntion类型的已经运行过了,这里直接跳过
continue
}
var err error
// 这里的i和前面Function的互补,Function中没有赋值的results中的元素就在这里赋值了;
// 注意到这里调用了一个Map函数就直接赋值给了results[i][index],这里的index是第一行这个
// 匿名函数的形参,通过ParallelizeUntil这个并发实现所有node对应一个优选算法的分值计算;
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Host = nodes[index].Name
}
}
})
for i := range priorityConfigs {
// 没有定义Reduce函数就不处理;
if priorityConfigs[i].Reduce == nil {
continue
}
wg.Add(1)
go func(index int) {
defer wg.Done()
// 调用Reduce函数
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if klog.V(10) {
for _, hostPriority := range results[index] {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), hostPriority.Host, priorityConfigs[index].Name, hostPriority.Score)
}
}
}(i)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
Map-Reduce的逻辑和Function类型的优选算法逻辑大体一致,其思路都是通过Pod对每个Node遍历调用优选算法计算每个Node的分数,得到上面提到的Node-Score对应的二维数组,下面开始对该数组进行整合(Combine)。
Combine组合结果集
Combine的过程非常简单,只需要将Node名字相同的分数进行加权求和统计即可。
// Summarize all scores.
// 这个result和前面的results类似,result用于存储每个node的Score,到这里已经没有必要区分算法了;
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
// 循环执行len(nodes)次
for i := range nodes {
// 先在result中塞满所有node的Name,Score初始化为0;
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
// 执行了多少个priorityConfig就有多少个Score,所以这里遍历len(priorityConfigs)次;
for j := range priorityConfigs {
// 每个算法对应第i个node的结果分值加权后累加;
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
return result, nil
最终得到一维数组HostPriorityList,也就是前面提到的HostPriority结构体的集合:
type HostPriority struct {
Host string
Score int
}
type HostPriorityList []HostPriority
就这样实现了为每个Node的打分Priority优选过程。