1. Brief description
This article takes the NVIDIA L40s GPU device as an example to briefly describe its GPU topology and the current CPU core-binding capabilities of Kubernetes. To briefly review, the NVIDIA L40s GPU device topology is shown in the figure below:
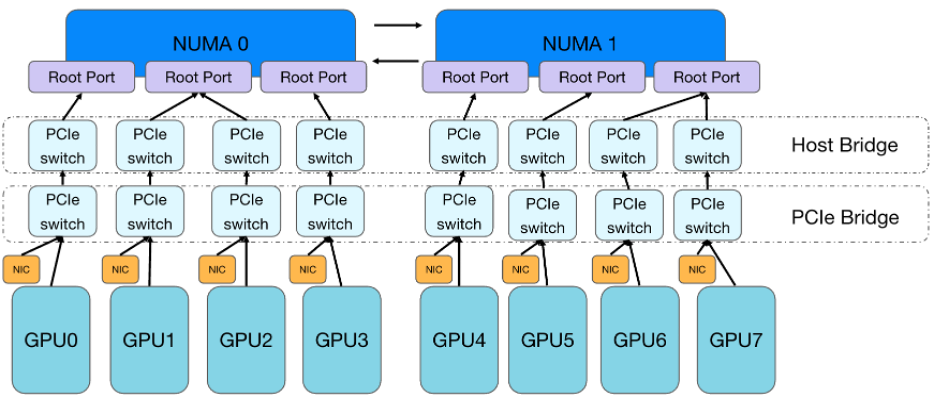
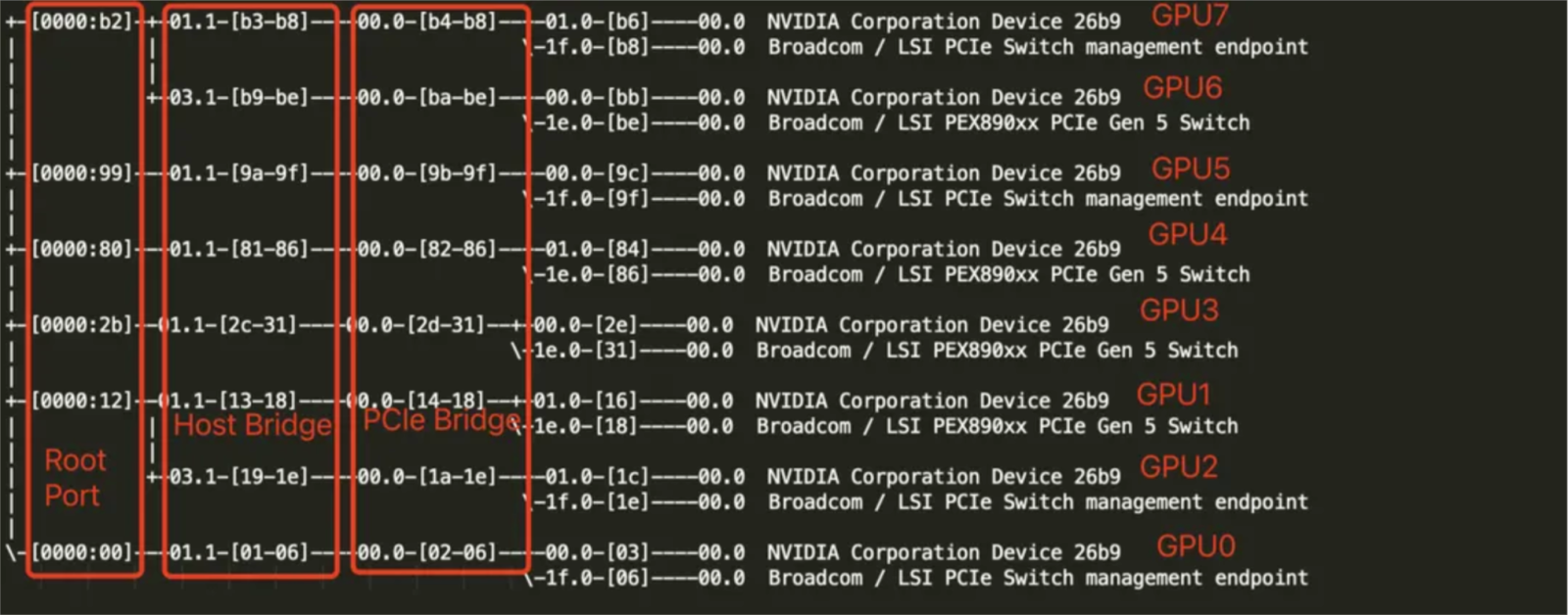
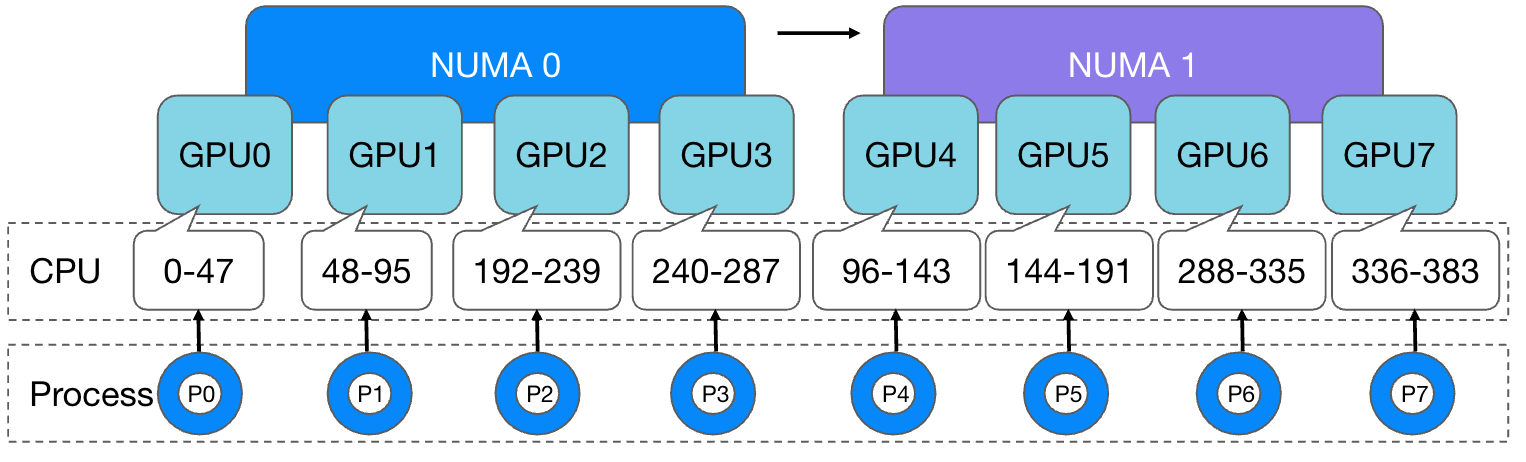
The CPU of this model has a total of 384 cores, distributed on 2 NUMA nodes. Each GPU has a mellanox high-speed RDMA network card and is hung under the same PCIe Bridge. The GPU and GPU are interconnected across two layers of PCIe switches. The kubernetes cluster currently has the ability to bind cores to the same NUMA CPU. For tasks with 4 cards or less, we use the best-effort strategy to meet the NUMA topology alignment as much as possible and bind the task process to the CPU core of the same NUMA node.
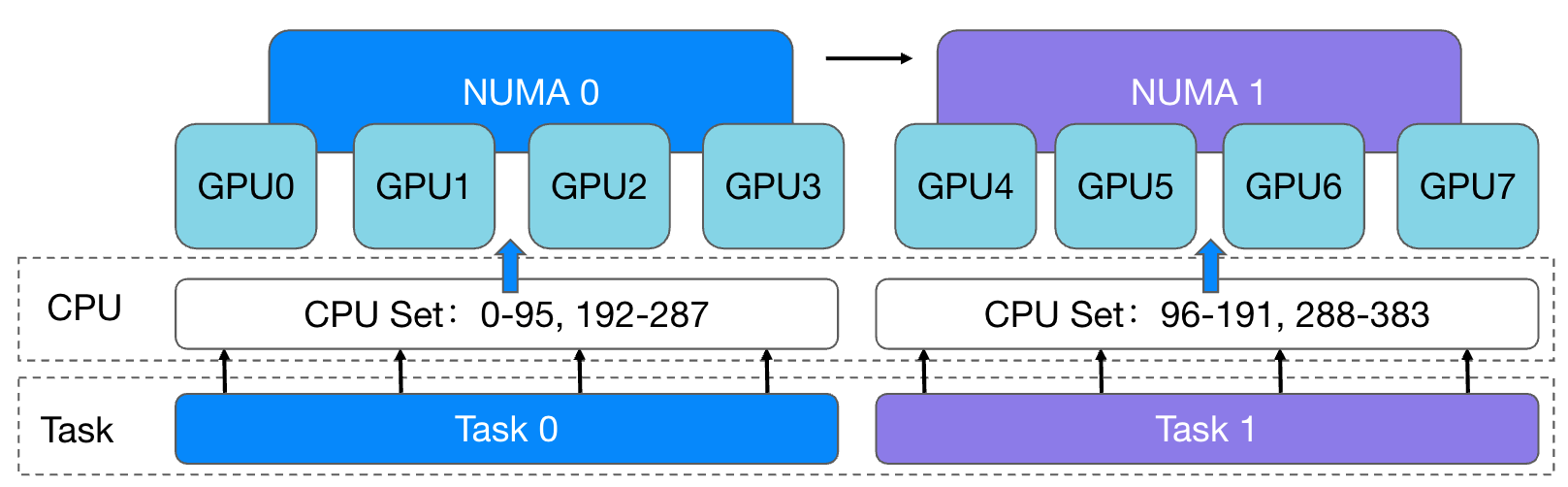
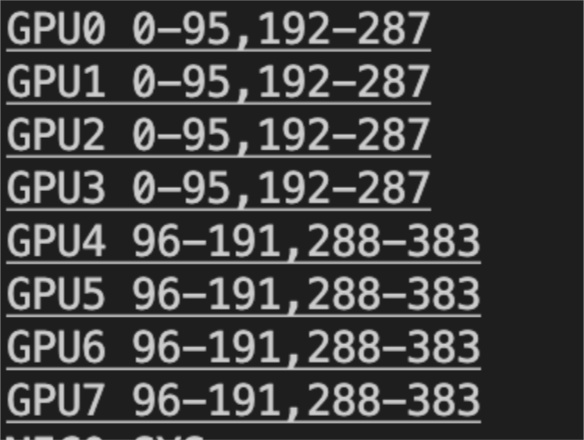
As shown in the figure above, GPU 0-3 cards are allocated to the container task Task 0, and CPU 0-95 and 192-287 cores under NUMA 0 are also bound. Allocate GPU 4-7 cards to container task Task 1, and bind CPU 96-191, 288-383 cores under NUMA 1. After implementing the core-binding strategy of aligning the same NUMA node topology, the 4-card task can prevent the process from accessing memory across NUMA nodes when using the CPU and GPU, and task performance has been improved to a certain extent. However, the current NUMA topology alignment and CPU core binding capabilities of the cluster may not be fully applicable in certain task scenarios. In order to support more diverse core-binding scenarios, based on the existing core-binding strategy, we have expanded the ability of containers to allocate results based on GPU cards to the nearest and proportionally bound CPU cores.
2. Issue description
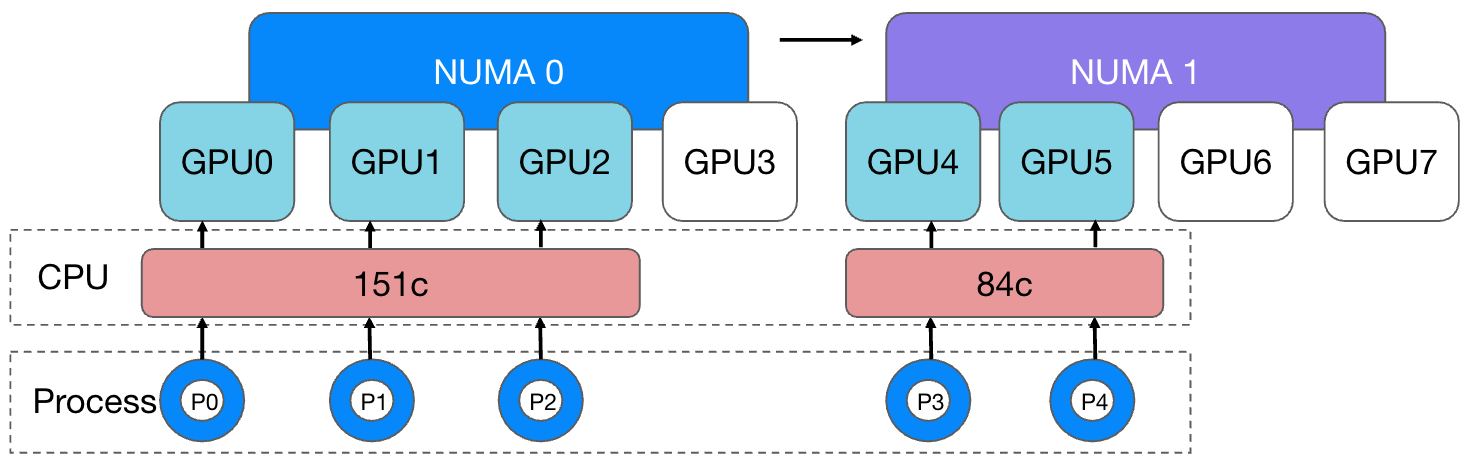
Various types of tasks are run in the cluster. In some scenarios, a large number of memory applications will occur. For example: In some machine learning training tasks, multi-batch parallel training is used, which means that at the beginning of each round of training, the GPU needs to load a large amount of data from the memory at one time. When performing a large number of memory copies, a large amount of PCIe bandwidth needs to be used for data exchange between devices. At the same time, the model size of the task is much smaller than that of a general large model, so the amount of data communicated between cards during training is small. In devices that do not have NVLink, even if inter-card communication is performed across NUMA nodes, it will not have any impact on other training performance. There will be a greater impact. Therefore, in terms of GPU allocation strategy, we allow tasks to be allocated GPU across NUMA nodes. During the actual running of training tasks, the user side found that several tasks would experience process freezes every day, which would cause individual processes to fail to train normally, resulting in a lower efficiency of the entire training task. For example: the GPU and CPU allocation of the 5-card training task process currently running in the cluster is as shown below:
In the L40s machine, the total CPU count is 384c, evenly distributed across 2 NUMA nodes:

The NUMA affinity relationship between GPU and CPU is as follows: (GPU0-3 is affinity to the CPU in NUMA 0, GPU 4-7 is affinity to the CPU in NUMA 1)
A machine is equipped with 8 GPU cards, and it is expected that an average of 48 cores of CPU will be allocated to the process of each GPU card (to simplify the content, the additional CPU cores reserved for system processes are not considered here), but the actual situation is:
- The CPU cores available to each process in different NUMA nodes are uneven:
- 3 GPU cards are allocated in NUMA 0 for the container process. Ideally 48*3 = 144 cores should be allocated. Since no CPU allocation strategy is used, 151 cores may actually be allocated.
- 2 GPU cards are allocated in NUMA 1 for the container process, ideally 48*2 = 96 cores should be allocated, but in reality 84 cores may be allocated.
- The training process is not bound to the CPU core and is completely scheduled and allocated by the operating system. There may be access to the CPU and memory across NUMA nodes.
This accordingly brings about two potential problems:
- When a process uses a certain GPU card, it also needs to exchange data with the memory. At this time, if a large amount of data is exchanged across NUMA between the GPU, CPU, and memory, the bandwidth will become a bottleneck.
- The available CPU and memory allocated to each process are unbalanced, resulting in some processes processing data quickly and some processes processing data slowly. At the same time, the memory usage of different NUMA nodes is uneven. NUMA nodes with high memory usage are more likely to run out of memory, causing some processes to freeze, ultimately slowing down the progress of the entire training task.
Therefore, in order to solve the problem of reduced task training performance in large memory scenarios, the cluster needs to have the following capabilities:
- Bind the same number of CPU cores to container processes evenly as much as possible, so that each process can exclusively occupy the CPU core and its memory usage is more balanced.
- Bind the GPU used by the container process to the CPU core under the same NUMA node accordingly to avoid communication between the GPU and CPU across NUMA nodes.
3. Solution
1. Kubernetes Community Initiative
The task runs in the Kubernetes cluster at the bottom of Taiji in the form of a container. Generally, the CPU core binding of the container is implemented through the kubelet component. Kubelet natively provides the following core binding strategies:
- full-pcpus-only: Allocate full physical cores.
- distribute-cpus-across-numa: The static policy distributes CPU evenly across NUMA nodes in situations where multiple NUMA nodes are needed to satisfy the distribution.
- align-by-socket: Allocate CPU according to CPU socket alignment.
- distribute-cpus-across-cores: Try to distribute virtual cores (hardware threads) to different physical cores.
Since the task also uses GPU devices, it is also necessary to align the PCIe devices with the CPU in NUMA topology. Kubelet also provides the following alignment strategies natively:
- none: Do not perform any topological alignment.
- best-effort: Consider NUMA affinity (not mandatory) when allocating devices, and allocate devices to the same NUMA node as much as possible.
- restricted: Consider NUMA affinity (mandatory) when allocating devices, and allocate devices to the same NUMA node.
- single-numa-node: Single NUMA node affinity, only allows devices to be allocated to containers within one NUMA node, and does not allow NUMA binding of devices across devices.
As mentioned in the previous requirement analysis, based on task performance considerations, tasks have two main requirements for the cluster:
- Assign the CPU and GPU bound to the same NUMA node to the task process.
- When using each GPU card, the same number of CPU cores can be bound to each GPU process at the same time, making the memory usage of different NUMAs more even.
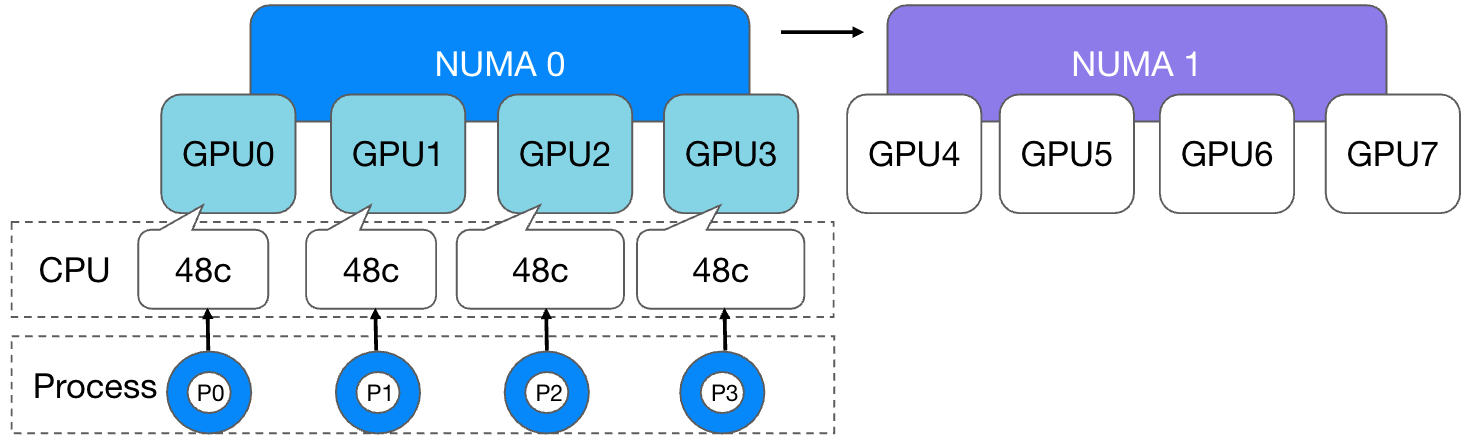
Just imagine, if we adopt the restricted or single-numa-node strategy, when the number of GPU cards requested by the task is 1-4 cards, kubelet will allocate the GPU device under the same NUMA node to the GPU and bind the same NUMA to the container. CPU core under node:
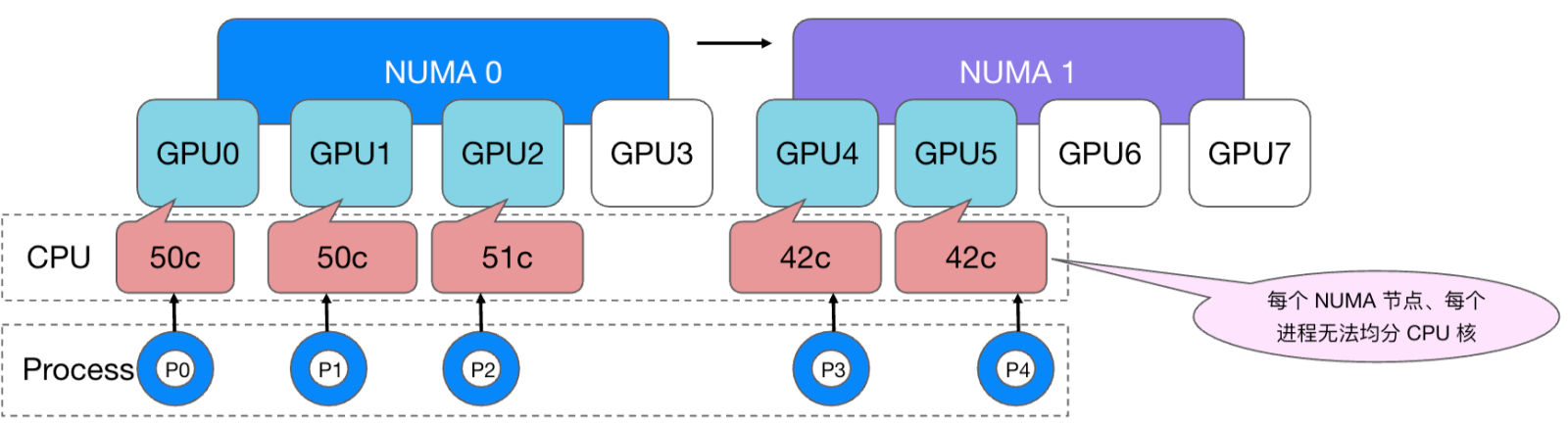
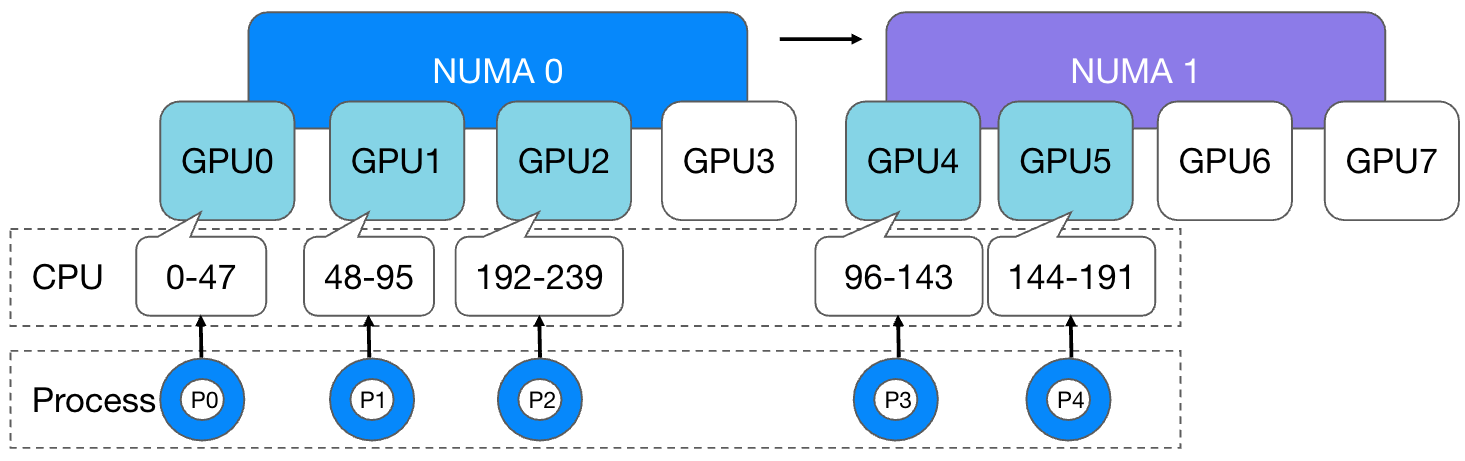
However, if the number of GPU cards applied for by a task exceeds 4 cards, for example, 5 cards, there will inevitably be at least one GPU allocated across NUMA. At this time, there is no strategy in the kubelet that can allocate GPUs across NUMA nodes. The same proportion of CPU cores is bound to the container. In this case, the cores are bound and each process cannot use the memory evenly:
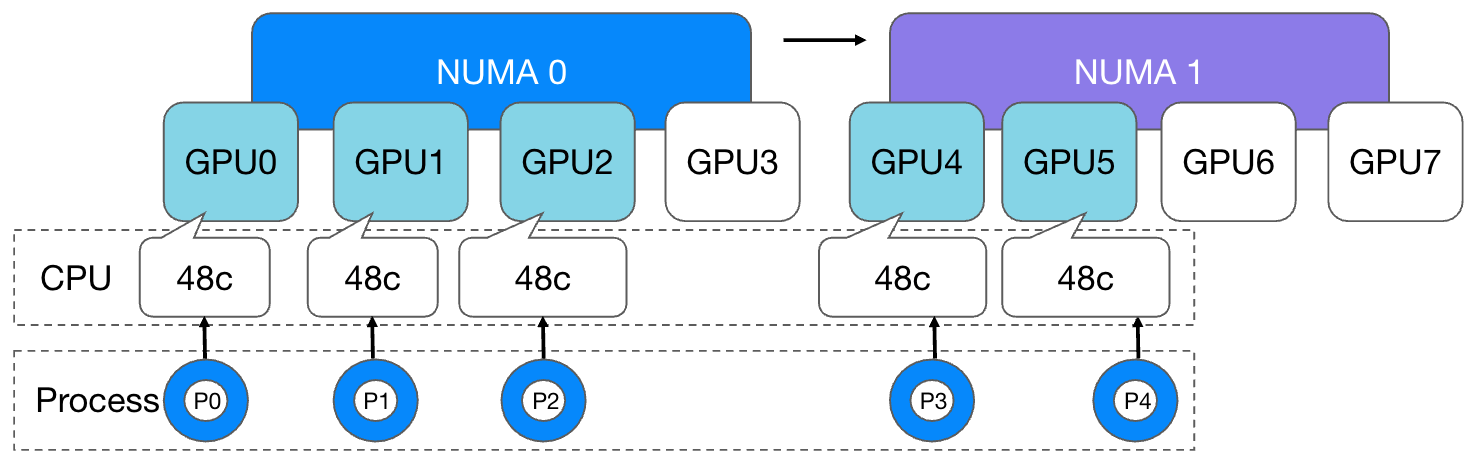
And we expect that each process can evenly allocate CPU cores and use memory evenly:
Therefore, the current Kubernetes community’s CPU core-binding and NUMA-affinity capabilities cannot meet the user’s needs of “equally allocating cores based on allocated GPU cards”.
2. GPU Worker custom cpuset solution
As mentioned earlier, the kubelet component natively supports various customized CPU core binding strategies in order to expand a richer core binding strategy and avoid conflicts with the core binding operations of the kubelet itself. We have separated the function of container CPU core binding from kubelet, and supported customized core binding operations for containers through self-developed components.
a) Overview
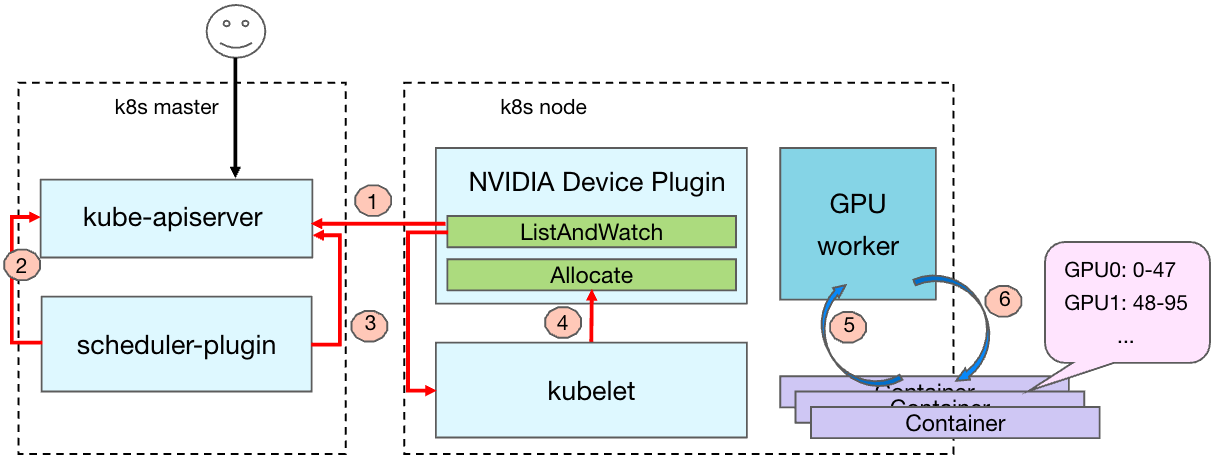
The above is the flow chart of the production, scheduling and core binding of the task container after the GPU training task is issued in the Kubernetes cluster. The overall process is as follows:
- Go to the Device Plugin component on the GPU node to report the number and status of the GPU cards available to the node to the central control component.
- The user submits a request to create a container task to the control plane, and the scheduler-plugin starts scheduling the task.
- After the scheduler completes scheduling, it synchronizes the scheduling results to kube-apiserver.
- At this time, the kubelet of the corresponding node senses that the task needs to be run on the node, starts to create the container, and allocates the corresponding GPU card to the container.
- The GPU worker component dynamically senses that new containers are created on the bottom layer.
- The GPU worker component starts to calculate the required CPU cores for the container to bind according to the core binding policy, issues the core binding configuration, and implements the core binding operation.
b) cpuset strategy Based on kubelet’s original cpuset strategy, the platform has expanded the strategy of “setting CPU cores proportionally based on GPU cards”.
As shown in the figure above, the allocation strategy ensures that each GPU card is evenly allocated the same number of CPU cores in the same NUMA node. For example: when a process uses GPU card No. 0, it is set to CPU cores No. 0-47 in proportion. . In the same way, when using GPU card No. 1, it is set to CPU cores No. 48-95, and so on. This allocation strategy ensures that the GPU and CPU used by the process communicate within the same NUMA node, and each GPU can have an equal proportion and the same number of CPU cores to communicate with it, making the CPU and memory usage of each process more balanced. When the platform has the ability to allocate CPU cores in the same NUMA node proportionally according to the GPU cards used by the tasks, the platform’s 5-card GPU task CPU allocation is as shown in the following figure:
The kubelet allocates a total of 5 GPU cards, 0, 1, 2, 4, and 5, to this task. The GPU worker component accordingly allocates 48 core CPUs evenly to each process, and the CPU cores bound to each process are all in Within the same NUMA node. By evenly dividing and bundling cores, each business process can use the CPU and memory evenly, and the memory usage of different NUMA nodes can also be effectively controlled, avoiding task lags caused by uneven memory usage.
4. Verification test
In order to verify the effect of the cpuset strategy, we issued a 5-card test task, corresponding to 5 training processes, and compared the memory distribution difference of the training performance of the process with NUMA evenly distributed cores and no core-binding process: a) Do not configure cpuset When cpuset is not configured for its processes, the processes experience heavy traffic across NUMA memory accesses, with each process having heavy and uneven memory usage across both NUMA nodes.
| GPU | NUMA 0 | NUMA 1 | |
|---|---|---|---|
| Process 0 | 0 | 46751.04 MB | 7224.73 MB |
| Process 1 | 1 | 38908.99 MB | 15949.48 MB |
| Process 2 | 2 | 51173.34 MB | 3304.10 MB |
| Process 3 | 4 | 7056.15 MB | 47357.92 MB |
| Process 4 | 5 | 14313.13 MB | 39988.64 MB |
b)Evenly distribute cpuset After the equally distributed cpuset policy is turned on, the process almost only accesses the memory of the process in the NUMA node with the same GPU. As can be seen from the test results in the table below, processes 0-2 use card 0-2 GPUs, proportionally bound to the CPU and memory in NUMA 0. Processes 3 and 4 use card 4 and 5 GPUs and are proportionally bound to the CPU and memory in NUMA 1.
| GPU | NUMA 0 | NUMA 1 | |
|---|---|---|---|
| Process 0 | 0 | 74439.49 MB | 377.46 MB |
| Process 1 | 1 | 74217.68 MB | 373.72 MB |
| Process 2 | 2 | 74198.02 MB | 373.68 MB |
| Process 3 | 4 | 216.87 MB | 73986.87 MB |
| Process 4 | 5 | 216.87 MB | 74891.98 MB |
After comparison testing, it was found that when the cpuset of the same NUMA node is configured proportionally, the training throughput is improved, the latency of swapping in and out of video memory and memory is significantly reduced, and the task does not freeze during the training process. Condition.
5. Summary
This article takes the NVIDIA L40s model as an example to describe the problems of lagging and poor performance encountered by some tasks when using this model for large-memory multi-batch parallel training. It conducts an in-depth analysis of the causes and locates the problem of process cross-processing. NUMA nodes access memory and the memory usage is uneven. Then we developed a core-binding component to implement a customized CPU equalization configuration cpuset strategy that is different from the Kubernetes community, and ultimately improved task performance.