1. Problem description
The pod test-pod-hgfmk under the test-pod-hgfmk namespace is in the pending state, and the nominated node is the 132.10.134.193 node
$ kubectl get po -n test-ns test-pod-hgfmk -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
test-pod-hgfmk 0/1 Pending 0 5m <none> <none> 132.10.134.193
The describe pod event found that scheduling failed due to insufficient cpu and memory resources, but monitoring found that there were many nodes with sufficient resources in the cluster.
2. Preliminary judgment
It is suspected that the resource information cached by the node in the scheduler is different from the real node allocable resources. Dump the scheduler node cache for comparison:
Actual resource usage of the node (kubectl describe node ):
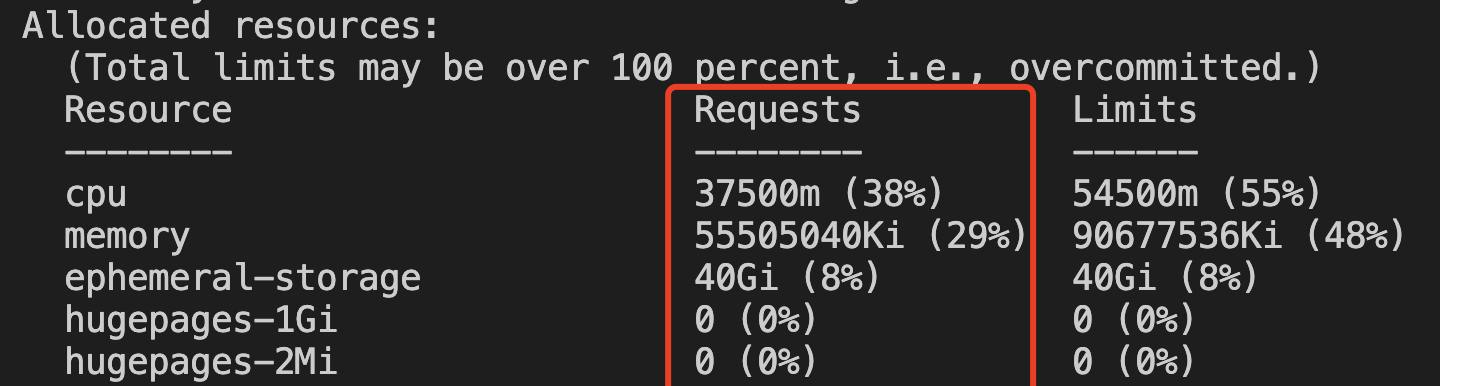
Node resource information currently cached by the scheduler (kill -SIGUSR2 ):
// Node information
{"log":"Node name: 132.10.134.193\n","stream":"stderr","time":"2021-10-16T08:06:42.929073912Z"}
// Node requests information (consistent with the picture above)
{"log":"Requested Resources: {MilliCPU:37500 Memory:56837160960 EphemeralStorage:42949672960 AllowedPodNumber:0 ScalarResources:map[teg.tkex.oa.com/amd-cpu:36000 tke.cloud.tencent.com/eni-ip:1]}\n","stream":"stderr","time":"2021-10-16T08:06:42.929076647Z"}
// Node allocable information (total allocable resources)
{"log":"Allocatable Resources:{MilliCPU:98667 Memory:191588200448 EphemeralStorage:482947890401 AllowedPodNumber:110 ScalarResources:map[hugepages-1Gi:0 hugepages-2Mi:0]}\n","stream":"stderr","time":"2021-10-16T08:06:42.929079502Z"}
// Node pod information
{"log":"Scheduled Pods(number: 3):\n","stream":"stderr","time":"2021-10-16T08:06:42.929085774Z"}
{"log":"name: ip-masq-agent-8v5lm, namespace: kube-system, uid: eee008d9-52ba-4c6d-ba7a-993a9c255718, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929102926Z"}
{"log":"name: kube-proxy-7sb7d, namespace: kube-system, uid: c53ef512-59f9-4afc-aa32-5f327b1e441d, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929105692Z"}
{"log":"name: node-exporter-p6rr4, namespace: kube-system, uid: dec7d32d-0652-430e-a013-ac40404a8428, phase: Running, nominated node: \n","stream":"stderr","time":"2021-10-16T08:06:42.929122523Z"}
{"log":"Nominated Pods(number: 1):\n","stream":"stderr","time":"2021-10-16T08:06:42.929125529Z"}
// This pod is the pending pod that appears this time
{"log":"name: test-pod-hgfmk, namespace: test-ns, uid: ae6fea01-ba91-4a34-9c10-b57f04f2fbf7, phase: Pending, nominated node: 132.10.134.193\n","stream":"stderr","time":"2021-10-16T08:06:42.929128224Z"}
Found that the cached information is consistent with the actual information
3. Build a test Pod to simulate the scheduling process
Construct a test deployment with the same business request value and taint tolerance conditions, and specify the nominated node scheduling that appears above through nodeSelector:
cat << EOF > ./test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: test-schedule
name: test-schedule
spec:
replicas: 1
selector:
matchLabels:
app: test-schedule
template:
metadata:
labels:
app: test-schedule
spec:
nodeSelector:
kubernetes.io/hostname: 132.10.134.193
containers:
- image: mirrors.tencent.com/tkestack/nginx:1.7.9
name: test-schedule
resources:
limits:
cpu: "70"
memory: 100Gi
requests:
cpu: "53"
memory: 70Gi
tolerations:
- effect: NoSchedule
key: zone/ap-gz-3
operator: Exists
- effect: NoSchedule
key: zone/ap-gz-5
operator: Exists
- effect: NoSchedule
key: zone/ap-gz-6
operator: Exists
EOF
kubectl create -f test.yaml
It was found that using the same requests value and stain as the business can be successfully scheduled.
3. Cause analysis
According to the scheduler code breakdown, the conditions for a Pod to appear as a nominated node are:
-
- When the Pod passes the filter scheduling algorithm, no Node can meet the requirements, and the Pod is configured with PriorityClass priority (the priority of all business Pods in the cluster currently defaults to 0)
-
- After evicting Pods with a lower priority than the Pod on all nodes in the cluster, let the Pod to be scheduled go through the filter scheduling algorithm. If any Node that meets the requirements is found, the Pod is considered to be able to participate in preemption. And randomly select one of these Nodes that meets the requirements as the nominated Node
However, looking at the node of this Pod nominatd, we found that the resources are completely sufficient for the business Pod, which means that this Pod cannot pass the filter algorithm in the first round of normal scheduling, but can pass the filter algorithm in the preemption stage . Theoretically, the same filter algorithm is used whether during normal scheduling or preemption. Why are the results of running the filter algorithm twice inconsistent? The difference is that the filter of the default scheduler + the filter of the extended scheduler is called during normal scheduling, while only the filter of the default scheduler is called during preemption (under the premise that the preemption function of the extended scheduler is not configured)
Code breakdown
Let’s take a look at the logic of scheduler preemption and the process of generating nominated nodes:
// pkg/scheduler/core/generic_scheduler.go
func (g *genericScheduler) Preempt(ctx context.Context, prof *profile.Profile, state *framework.CycleState, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
...
...
// 1. Obtain all node information of the cluster from the cache snapshot
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
...
// 2. Use all healthy nodes in the cluster as alternative nominated nodes
potentialNodes := nodesWherePreemptionMightHelp(allNodes, fitError)
...
// 3. Select the node that can truly become the nominated node from the candidate nominated nodes.
// Condition: After removing all pods with lower priority than this pod on the node, and then running the filter scheduling algorithm again, if there is a node in the cluster that meets the conditions, it will be regarded as the nominated node
nodeToVictims, err := g.selectNodesForPreemption(ctx, prof, state, pod, potentialNodes, pdbs)
...
// 4. Not only do you need to use the preemption logic of the default scheduler, but you also need to use the preemption logic of the extended scheduler, and then filter a batch of nominated nodes.
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
...
// 5. Finally, the remaining nominated nodes randomly select a nominated node as the pod.
candidateNode := pickOneNodeForPreemption(nodeToVictims)
...
return candidateNode, nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
Steps 3 and 4 in the above process are the key steps to generate nominated node:
- In step 3, the scheduler will determine whether the business Pod can pass the scheduler’s filter scheduling algorithm (default scheduler) after evicting the Pod with a lower priority than the business Pod on all nodes in the cluster. If it can pass, Treat this batch of nodes that pass the filter algorithm as nominated nodes. However, because the priorities of business Pods are equal by default, there are no low-priority Pods that need to be evicted. Therefore, it is equivalent to the cluster re-running the filter algorithm without making any changes. The node obtained at this time has sufficient resources and meets the scheduling conditions. A batch of nodes (including 11.134.132.193)
- In step 4, put the nominated nodes filtered out in the third step into the extended scheduler and run the preemption logic of the extended scheduler, then filter out a batch of nominated nodes that do not meet the conditions, and randomly select a node for the remaining ones. As the final nominated node of the business Pod.
The scheduler extender extension scheduler is configured in the cluster, and its preemption logic is:
// pkg/schedulerplugin/preempt.go
func (p *FloatingIPPlugin) Preempt(args *schedulerapi.ExtenderPreemptionArgs) map[string]*schedulerapi.MetaVictims {
fillNodeNameToMetaVictims(args)
// 1. Analyze the pod’s IP release strategy (never release IP, release IP when scaling down, do not retain IP)
policy := parseReleasePolicy(&args.Pod.ObjectMeta)
// 2. If the IP release policy of the pod is not to retain the IP, there is no need to filter the nominated node and return it directly.
if policy == constant.ReleasePolicyPodDelete {
return args.NodeNameToMetaVictims
}
// 3. Get the subnet to which the business Pod belongs (because of the fixed IP policy, the subnet to which the pod's previous IP belongs is saved in the fip object)
subnetSet, err := p.getSubnet(args.Pod)
for nodeName := range args.NodeNameToMetaVictims {
node, err := p.NodeLister.Get(nodeName)
// 4. Get the subnet of the alternative nominated node
subnet, err := p.getNodeSubnet(node)
if err != nil {
glog.Errorf("unable to get node %v subnet: %v", nodeName, err)
// 5. If the eni-provider cannot be adjusted to obtain the node subnet, filter out these nodes.
delete(args.NodeNameToMetaVictims, nodeName)
continue
}
// 6. If the node subnet does not match the original subnet of the pod, these nodes will also be filtered out.
if !subnetSet.Has(subnet.String()) {
glog.V(4).Infof("remove node %v with subnet %v from victim", node.Name, subnet.String())
delete(args.NodeNameToMetaVictims, nodeName)
}
}
// 7. Return the filtered nominated node
return args.NodeNameToMetaVictims
}
Scheduling process analysis
As mentioned earlier, the business Pod** cannot pass the filter algorithm in the first round of normal scheduling, but can pass the filter algorithm** in the preemption stage. This is probably because the preemption logic of the extended scheduler was not successfully executed and the nominated node was not Filtered out, so the pod is set to nominated node. This process corresponds to step 4 in the figure below. Nominated nodes that are not in the same subnet as the fixed IP Pod are not filtered out. Instead, the nominated node generated in step 3 (equivalent to only the filter in step 1) is directly used as a pod. The candidate node causes the pod to be bound to the nominated node.
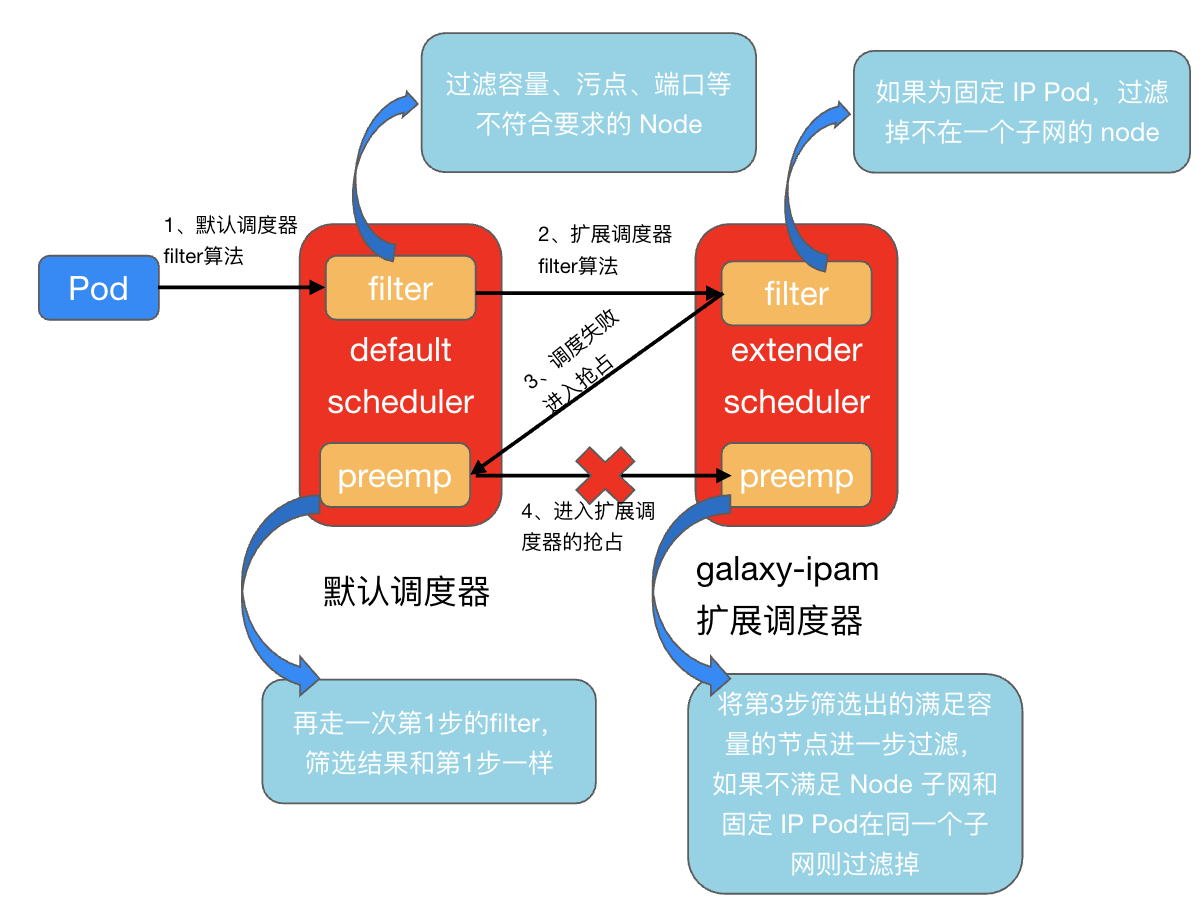
Check the node’s scheduler configuration. The preemption configuration of the extended scheduler is indeed missing:
$ cat /etc/kubernetes/schduler-config.json
{
"apiVersion": "kubescheduler.config.k8s.io/v1alpha2",
"kind": "KubeSchedulerConfiguration",
"leaderElection": {
"leaderElect": true
},
...
"extenders": [
{
"apiVersion": "v1beta1",
"enableHttps": false,
"filterVerb": "filter",
"BindVerb": "bind",
"weight": 1,
// 抢占配置
//"preemptVerb": "preempt",
"nodeCacheCapable": false,
"urlPrefix": "http://sheduler-extender:1003/v1",
}
]
}
The following figure shows the entire scheduling process of business pods:
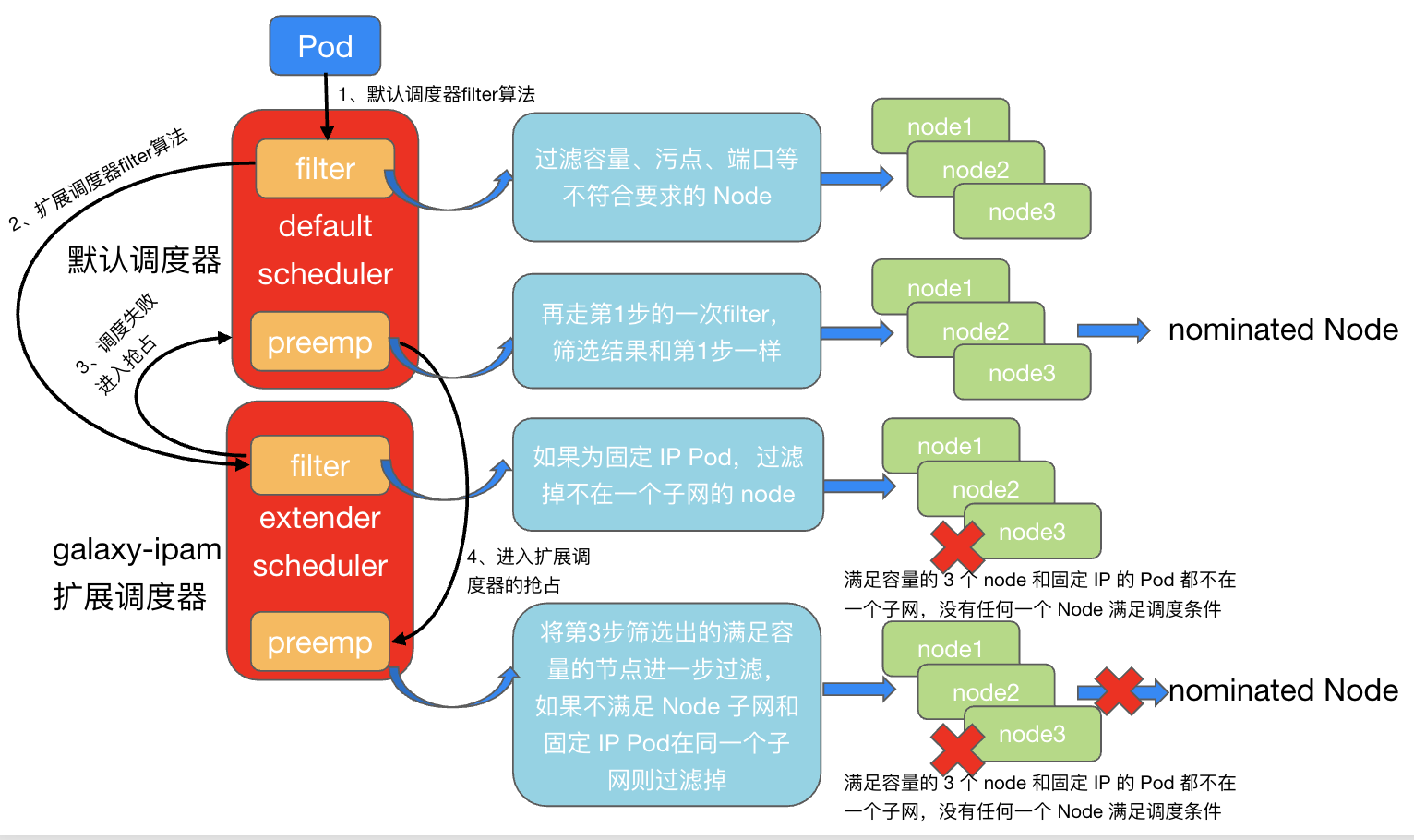
Step 1: The business Pod enters the filter algorithm of the default scheduler and filters out the nodes that meet the capacity, label, and taint. At this time, the only few nodes with idle capacity in the cluster are filtered out and enter the next step.
node1: 188.10.151.196
node2: 132.10.134.108
node3: 132.10.134.193
node4: 191.10.151.38
node5: 132.10.134.212
node6: 190.10.151.195
node7: 190.10.151.202
Step 2: Enter the filter algorithm of the extended scheduler sheduler-extender. Because the IP release policy of the business Pod is to be released when the capacity is reduced, the extender reserves the IP for the Pod. In the filter algorithm, the 7 filtered out in the first step will be judged sequentially. Whether the nodes are in the same subnet as the business Pod (only nodes in the same subnet can allocate the last fixed IP to the Pod). At this time, the 7 nodes are not satisfied (the capacity of the nodes that meet the requirements of the same subnet is insufficient. In The first step has been filtered), scheduling fails, and preemption is entered. Step 3: Entering the preemption of the default scheduler is equivalent to going through the filter of the first step again, filtering out the nodes that meet the capacity, label, and stain again, and entering the preemption logic of the extended scheduler as nominated nodes (if not configured Expanding the preemption logic of the scheduler will return directly and randomly bind a nominated node to the pod. This is the fundamental reason why nominated pods appear.)
node1: 188.10.151.196
node2: 132.10.134.108
node3: 132.10.134.193
node4: 191.10.151.38
node5: 132.10.134.212
node6: 190.10.151.195
node7: 190.10.151.202
Step 4: Enter the preemption of the extended scheduler, and further filter the nodes that meet the capacity, label, and taint filtered out in the third step. If the Node subnet and the fixed IP Pod are not in the same subnet, filter them out. Finally, All nominated nodes are filtered out, and no pending pods in the nominated state will be generated. After enabling preemption of the extended scheduler, nominated pods no longer appear in the cluster:
$ kubectl get po -n test-ns test-pod-bvtjg -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
test-pod-bvtjg 0/1 Pending 0 5m <none> <none> <none>
4. Summary
-
- The reason why nominated pods appear: The scheduler does not enable the preemption configuration of the extended scheduler. As a result, nodes (nominated nodes) that meet the Pod capacity, label, and taint requirements but are not in the same subnet as the fixed IP Pod are not filtered out. .
-
- The reason why pending pods appear is not because the cluster is completely out of resources, but because some services have enabled the fixed IP (released during scale-down) policy, which causes the original node resources to be preempted by other services when the Pod is rebuilt, and the resource requirements are not met. The node and Pod are not in the same subnet, causing scheduling failure.