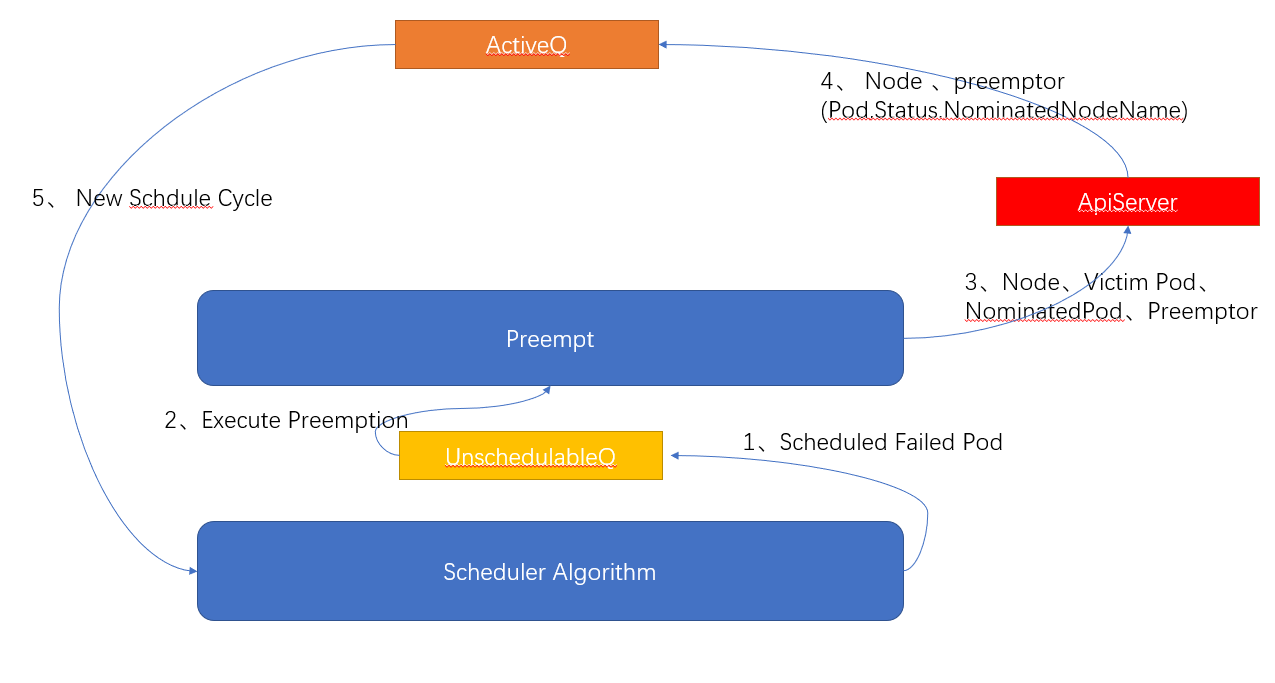
1. Priority and preemption mechanism
During the scheduling process, Kube-scheduler takes out the Pod from the scheduling queue (SchedulingQueue) each time and performs one round of scheduling. So in what order are the Pods in the scheduling queue added to the queue? The Pod resource object supports setting the Priority attribute. Through different priorities, Pods with high priority are placed in front of the scheduling queue and scheduled first. If the scheduling of a Pod with a high priority fails and no suitable node is found, it will be placed in the UnschedulableQueue and enter the preemption phase. The Pod with a low priority on the node will be evicted in the next scheduling.
How to set priority for Pod? Just create a PriorityClass resource object:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: ""
Use PriorityClass in pod:
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx-a
name: nginx-a
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx-a
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
memory: "64Mi"
cpu: 5
limits:
memory: "128Mi"
cpu: 5
priorityClassName: high-priority
Scheduling Framework is used in Kubernetes 1.19, and the scheduling algorithm is introduced in the form of a plug-in. For example, when prioritizing Pods before scheduling starts, the queue sorting plug-in (QueueSortPlugin) is used
// pkg/scheduler/framework/v1alpha1/interface.go
type QueueSortPlugin interface {
Plugin
// Less are used to sort pods in the scheduling queue.
Less(*QueuedPodInfo, *QueuedPodInfo) bool
}
The plug-in needs to implement the sorting comparison function Less(). The official Pod priority sorting algorithm Less() is implemented as follows:
// pkg/scheduler/framework/plugins/queuesort/priority_sort.go
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
Sort by getting the Priority value of the Pod, and the larger one will be ranked first. If the priorities are the same, the Pod created first will be compared based on the creation time.
2. Affinity Scheduling
Developers label Node and Pod resource objects accordingly, and the scheduler will use the labels to schedule Pods with affinity (Affinity) and anti-affinity (Anti-Affinity).
- Node Affinity: express the affinity relationship between Pod and Node, and schedule Pod to a specific node
- Pod Affinity: expresses the affinity relationship between Pods and schedules a group of Pods with close business operations to the same (group) node
- Pod Anti-Affinity: Express the anti-affinity relationship between Pods and Pods, and try not to schedule two Pods on the same (group) node
2.1 NodeAffinity
Setting this feature can schedule Pods to specific nodes. For example, IO-intensive Pods can be scheduled to machines with high IO device configurations, and CPU-intensive Pods can be scheduled to machines with high CPU cores. NodeAffinity supports two scheduling strategies:
- RequiredDuringSchedulingIgnoredDuringExecution: It is mandatory that Pods must be scheduled to nodes that meet the affinity. If the conditions are not met, Pod scheduling will fail and continue to retry.
- PreferredDuringSchedulingIgnoredDuringExecution: It is not mandatory that Pods must be scheduled on nodes that satisfy affinity. Nodes that satisfy affinity will be scheduled first. If neither is satisfied, other better nodes will be selected.
// vendor/k8s.io/api/core/v1/types.go
type NodeAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution *NodeSelector `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,opt,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []PreferredSchedulingTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
2.2 PodAffinity
Setting this feature can schedule a Pod to the same node as another Pod (or have the same affinity). This is mainly to shorten the network transmission delay of two Pods with close business and speed up the network transmission efficiency. Similar to NodeAffinity, PodAffinity also supports two scheduling strategies:
- RequiredDuringSchedulingIgnoredDuringExecution: It is mandatory that the Pod must be scheduled to a node that meets the affinity with other Pods (adjacent or the same as other Pods). If the conditions are not met, the Pod scheduling will fail and continue to retry.
- PreferredDuringSchedulingIgnoredDuringExecution: It is not mandatory that Pods must be scheduled on nodes that satisfy the affinity with other Pods (adjacent or the same as other Pods). Priority will be given to scheduling on nodes that satisfy the affinity. If neither is satisfied, other better alternatives will be selected. node
// vendor/k8s.io/api/core/v1/types.go
type PodAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution []PodAffinityTerm `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,rep,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []WeightedPodAffinityTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
2.3 PodAntiAffinity
Setting this feature can schedule a Pod to a different node where another Pod is located, mainly to achieve high availability of the Pod and reduce the risk of node failure. Similar to NodeAffinity and PodAffinity, PodAntiAffinity also supports two scheduling strategies:
- RequiredDuringSchedulingIgnoredDuringExecution: It is mandatory that Pods must not be scheduled to nodes that are exclusive of other Pods. If the conditions are not met, Pod scheduling will fail and keep retrying.
- PreferredDuringSchedulingIgnoredDuringExecution: It is not mandatory that Pods must not be scheduled to nodes that are exclusive of other Pods. Priority will be given to scheduling nodes that meet the conditions. If neither is satisfied, other better nodes will be selected.
// vendor/k8s.io/api/core/v1/types.go
type PodAntiAffinity struct {
RequiredDuringSchedulingIgnoredDuringExecution []PodAffinityTerm `json:"requiredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,1,rep,name=requiredDuringSchedulingIgnoredDuringExecution"`
PreferredDuringSchedulingIgnoredDuringExecution []WeightedPodAffinityTerm `json:"preferredDuringSchedulingIgnoredDuringExecution,omitempty" protobuf:"bytes,2,rep,name=preferredDuringSchedulingIgnoredDuringExecution"`
}
3. In-tree scheduling algorithm
The Scheduler Framework was introduced in Kubernetes version 1.19, which configures and runs in-tree scheduling algorithms in the form of plug-ins. Compared with the old version of the scheduling strategy, its core content has not changed, and it still uses two core scheduling algorithms:
- Predicate-based preselection algorithm (Predicate): Check whether the Pod to be scheduled can be scheduled to the candidate node. If the node’s hard conditions such as disk, memory, CPU, label, port, etc. do not meet the operating conditions of the Pod, directly This node is filtered and does not participate in the subsequent scheduling process.
- Priority-based optimization algorithm (Priority): Score each schedulable node according to various indicators, and select the node with the highest score as the optimal node for Pod scheduling.
In the source code of 1.19, the pkg/scheduler/framework/plugins directory provides various implementations of the in-tree scheduling algorithm for the Kubernetes scheduler:
Different algorithms may use multiple scheduling plug-ins. There are 11 main types of scheduling plug-ins:
- Queue sort Sort the Pods to be scheduled (by default, they are sorted according to the Priority value of the Pod)
- PreFilter Condition check before Pod scheduling. If the check fails, the scheduling cycle will be ended directly (for example: filtering pods with certain labels and annotations)
- Filter Filter out Nodes that do not meet the current Pod running conditions (equivalent to Predicate in the old version of the scheduler)
- PostFilter Executed after the Filter plug-in is executed, generally used for Pod preemption scheduling
- PreScore Perform relevant operations before node scoring
- Scoring Score nodes (equivalent to Priority in legacy schedulers) After the scoring is completed, the scores are normalized and transformed into a unified range (normalize) ((nodeScore.Score - lowest) * newRange / oldRange) + framework.MinNodeScore ((current score - minimum score) * ratio of scheduler default score range to actual score range) + scheduler default minimum score
- Reserve
- Permit Admission control before Pod binding – approve –deny – wait (with timeout)
- PreBind The logic before binding the Pod, such as: pre-mount the shared storage first and check whether it is mounted normally.
- Bind
- PostBind Resource cleanup logic after successful Pod binding
Whether it is an in-tree scheduling algorithm or a custom extended scheduling algorithm, it must be extended on the 11 officially provided plug-in interfaces, such as the in-tree NodeName scheduling algorithm, whose function is to filter out the nodes in the Pod except for the nodes set by the nodeName field. Other nodes need to use the Filter plug-in to execute the Predicate algorithm:
// pkg/scheduler/framework/interface.go
// The interface of the Filter plug-in. Any scheduler that uses this plug-in needs to implement its own Filter method to define the filtering rules of Node.
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
The following is the implementation of the in-tree preselection algorithm NodeName for the Filter plug-in:
// pkg/scheduler/framework/plugins/nodename/node_name.go
// Define a scheduler plugin structure named NodeName
type NodeName struct{}
// The NodeName scheduler plug-in is of type FilterPlugin and needs to implement the methods of the FilterPlugin interface.
var _ framework.FilterPlugin = &NodeName{}
// The Filter method is the implementation method of the FilterPlugin interface
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo.Node() == nil {
return framework.NewStatus(framework.Error, "node not found")
}
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}
// The core logic of the scheduler is that if the NodeName field of the Pod does not match the node name to be scheduled, it will be filtered out
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) bool {
return len(pod.Spec.NodeName) == 0 || pod.Spec.NodeName == nodeInfo.Node().Name
}
// Initialize scheduler plugin
func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &NodeName{}, nil
}
4. Thoughts on the scheduler expansion mechanism
In version 1.19, when we need to customize the extended scheduler, we can use the same routine as the official in-tree scheduling algorithm and implement the officially provided plug-in interface. We know that the old version of the Extended Scheduler (Scheduler Extender) is based on an external Webhook service. The customized extended scheduling algorithm needs to access our customized extended scheduler through an HTTP request after the official scheduling algorithm is executed. This extension method There will be many problems:
- The execution timing of the scheduling algorithm is inflexible The extended predicate and priority algorithms can only be executed after the scheduling algorithm of the default scheduler.
- Serialization and deserialization are slow The extended scheduler uses HTTP+JSON for serialization and deserialization.
- After calling the extended scheduler exception, the scheduling task of the current Pod is directly discarded. A notification mechanism is needed to make the scheduler aware of extended scheduler exceptions.
- Unable to share the cache of the default scheduler (because the extended scheduler and the default scheduler are in different processes)
The new version of the scheduler is based on the scheduler framework and is extended in the form of plug-ins. It can extend our own scheduling logic in any scheduling environment. It is very flexible, and the code of the expanded scheduler logic and official scheduler service is Coupled with each other and running in the same process, it avoids the instability and unnecessary overhead caused by network communication. It is the mainstream solution for scheduler expansion at present and even in the future, and the expanded scheduler mechanism based on external services will Slowly exit the stage of the official scheduler.