1. kube-scheduler architecture design
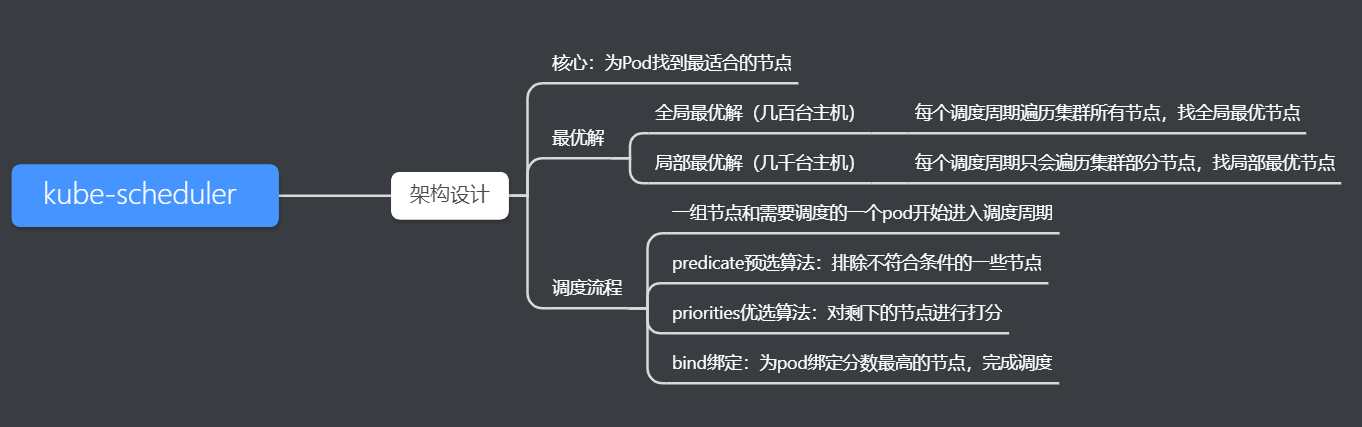
The core function of the scheduler is to find the most suitable node for the Pod to run on. For small-scale clusters, each scheduling cycle will traverse all nodes in the cluster to find the most suitable node for scheduling. For large-scale clusters, each scheduling cycle will only traverse some nodes in the cluster, and find the most suitable nodes among these nodes for scheduling. The entire scheduling process is mainly divided into three nodes: pre-selection, optimization and binding. The pre-selection phase first filters out nodes that do not meet the conditions, the optimization phase mainly scores the nodes filtered in the pre-selection phase, and the binding phase binds the nodes with the highest scores to pods to complete scheduling. This code breakdown is for Kubernetes V1.18.10 version
2. kube-scheduler component startup process
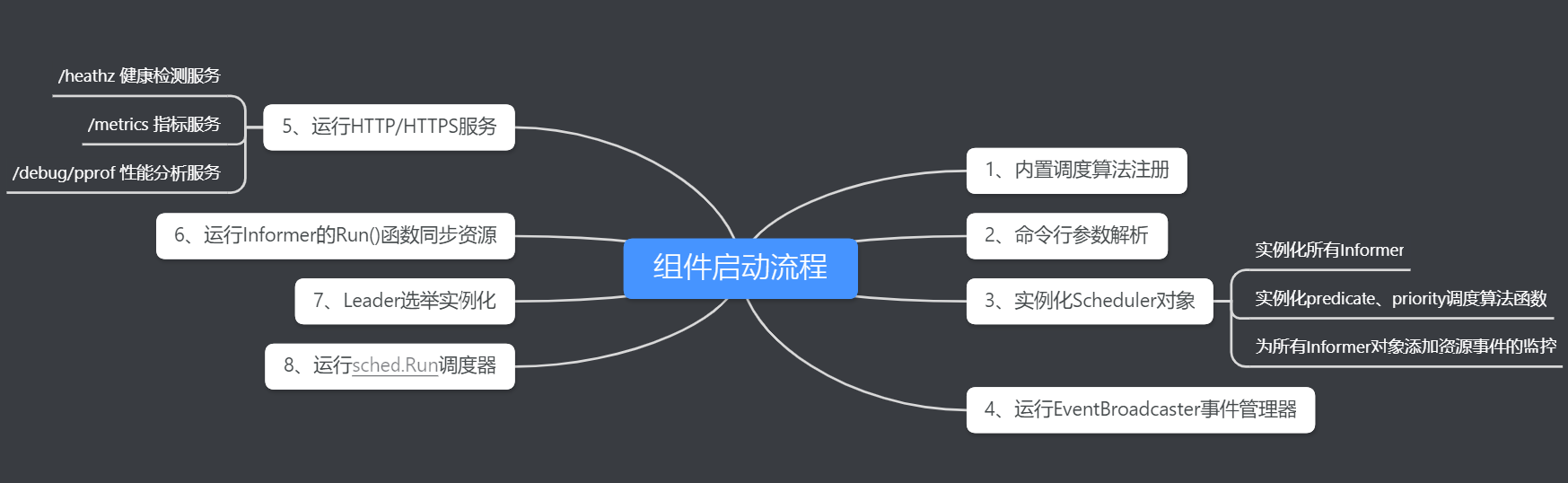
2.1 Built-in scheduling algorithm registration
Call algorithmprovider.NewRegistry() in the createFromProvider function to register the scheduler algorithm plug-in:
//pkg/scheduler/factory.go
func (c *Configurator) createFromProvider(providerName string) (*Scheduler, error) {
klog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
r := algorithmprovider.NewRegistry()
defaultPlugins, exist := r[providerName]
if !exist {
return nil, fmt.Errorf("algorithm provider %q is not registered", providerName)
}
for i := range c.profiles {
prof := &c.profiles[i]
plugins := &schedulerapi.Plugins{}
plugins.Append(defaultPlugins)
plugins.Apply(prof.Plugins)
prof.Plugins = plugins
}
return c.create()
}
The algorithmprovider.NewRegistry() function calls getDefaultConfig() to obtain the default scheduling algorithm and register it.
//pkg/scheduler/algorithmprovider/registry.go
func getDefaultConfig() *schedulerapi.Plugins {
return &schedulerapi.Plugins{
QueueSort: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: queuesort.Name},
},
},
PreFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.FitName},
{Name: nodeports.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
{Name: volumebinding.Name},
},
},
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
},
},
PostFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: defaultpreemption.Name},
},
},
PreScore: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name},
{Name: podtopologyspread.Name},
{Name: tainttoleration.Name},
},
},
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},
Reserve: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
PreBind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
Bind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: defaultbinder.Name},
},
},
}
}
What is set in Filter is the Predicate preselected algorithm plug-in list, and what is set in Score is the Priority preferred algorithm plug-in list. After all plug-ins are initialized, register them in the schedulerapi.Plugins{} scheduler plug-in list.
2.2 Cobra command line parameter analysis
Cobra is a command line parsing tool used in systems such as Kubernetes and Docker. The kube-scheduler component also uses Cobra for command line parsing.
//cmd/kube-scheduler/app/server.go
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
// Initialize the command line default configuration
opts, err := options.NewOptions()
...
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: ...
Run: func(cmd *cobra.Command, args []string) {
// The runCommand function parses and verifies command line commands and parameters.
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
...
return cmd
}
// runCommand parses and verifies command line commands and parameters.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cc, sched, err := Setup(ctx, opts, registryOptions...)
...
// Run the Run function to start the kube-scheduler component
return Run(ctx, cc, sched)
}
2.3 Instantiate Scheduler object
Scheduler object instantiation mainly instantiates the resource object’s Informer, scheduling algorithm and resource object event monitoring.
//cmd/kube-scheduler/app/server.go
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
...
// Create the scheduler.
// Instantiate the scheduler object
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
recorderFactory,
ctx.Done(),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
)
...
return &cc, sched, nil
}
The specific execution logic of the New function of instantiating the scheduler object
//pkg/scheduler/scheduler.go
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
...
// 1. Instantiate all Informers
configurator := &Configurator{
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
}
...
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// 2. Instantiation scheduling provider
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
...
}
...
// 3. Add monitoring of resource events to all Informer objects
addAllEventHandlers(sched, informerFactory)
return sched, nil
}
2.4 Run EventBroadcaster event manager
Event (event) is a resource object in Kubernetes and is used to describe events generated by the cluster. For example, during the scheduling process of the kube-scheduler component, decisions such as what is done with the scheduling of a certain Pod and why certain Pods need to be evicted are recorded by requesting the apiserver to create an Event. The newly created Event is retained for 1 hour by default.
//cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// Run EventBroadcaster
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
...
return fmt.Errorf("finished without leader elect")
}
2.5 Run HTTP or HTTPS service
Three HTTP services are provided in kube-scheduler: health detection, indicator monitoring, and pprof performance analysis. Corresponding to the three interfaces /healthz, /metrics, and /debug/pprof respectively.
//cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// Start /healthz health detection service
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
// Start /metrics metric monitoring
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
...
return fmt.Errorf("finished without leader elect")
}
2.6 Run Informer to synchronize resources
All Informer objects have been instantiated in 2.3, and they need to be run in this step.
//cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// Run all Informers
cc.InformerFactory.Start(ctx.Done())
// Wait for all Informer cache synchronization to complete
cc.InformerFactory.WaitForCacheSync(ctx.Done())
...
return fmt.Errorf("finished without leader elect")
}
2.7 Leader election instantiation
The controller-manager and kube-scheduler components in Kubernetes have Leader election mechanisms, which achieve high availability of distributed systems through leader election. The implementation principle is to callback and notify the kube-scheduler component of the current node whether the competition for Leader is successful by defining OnStartedLeading and OnStoppedLeading in the callback function leaderelection.LeaderCallbacks. The OnStartedLeading callback indicates that it has become the leader through election, so sched.Run is called to start the scheduler. The OnStoppedLeading callback indicates that the election to become the Leader failed and the Leader was preempted by another node. A Fatal log will be printed and the scheduler process will be exited directly.
//cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// Determine whether to open the election
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: sched.Run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
// Start a new round of elections
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
...
return fmt.Errorf("finished without leader elect")
}
2.8 sched.Run runs the scheduler
//cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// Run the scheduler
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
The following is the main logic of sched.Run(ctx). sched.scheduleOne executes the scheduling logic of the scheduler and executes it through the wait.UntilWithContext timer (the third parameter is 0, which means that the sched.scheduleOne function is executed again immediately after execution) , calling the sched.scheduleOne function regularly until the main coroutine notifies the ctx context through cancel.
//pkg/scheduler/scheduler.go
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}