1. Leader election process
In the raft protocol, a node is in one of the following three states at any time:
- leader: master node
- follower: slave node
- candidate: candidate master node
1. Election at startup:
When a node starts, it is in the follower state. If it does not receive a heartbeat from the leader within a period of time, it switches from follower to candidate and initiates an election. If it receives the majority of votes in the cluster (including its own vote), it will switch to the leader state; if it is found that other nodes have become the leader before itself, it will actively switch to the follower state.
2. Runtime election:
If the follower does not receive a heartbeat from the leader within the election timeout (maybe the leader has not been elected yet and everyone is waiting; maybe the leader has died; maybe there is just a network failure between the leader and the follower), it will actively initiate election. Proceed as follows:
- A node switches to candidate state and casts its vote
- Send RequestVote RPCs requests to other nodes in parallel (request to vote)
- Wait for replies from other nodes
During this process, three outcomes may occur based on messages from other nodes:
- If you receive votes from the majority (including your own vote), you will win the election and become the leader.
- If you are informed that someone else has been elected, then switch to the follower yourself
- If no majority vote is received within a period of time or two candidates have a tie vote, the candidate status will remain and the election will be reissued. Because frequent tie votes will cause nodes to constantly re-elect, resulting in long-term unavailability, Raft introduced randomized election timeouts to try to avoid tie votes (the election timeout of each node is random) ). At the same time, in the leader-based consensus algorithm, the number of nodes is an odd number, and try to ensure the occurrence of majority. ,
2、log replication
All requests from the client are sent to the leader, and the leader schedules the order of these concurrent requests and ensures the consistency of the leader and followers states. The approach in raft is to inform followers of these requests and the order of execution. The leader and followers execute these requests in the same order to ensure consistent status. The leader encapsulates the client request (command) into each log entry, replicates these log entries to all follower nodes, and then everyone applies (apply) the commands in the log entry in the same order, then the status must be consistent. The leader only needs the log to be copied to most nodes to return to the client. Once a success message is returned to the client, the system must ensure that the log (actually the command contained in the log) will not occur under any abnormal circumstances. rollback. There are two words here: commit (committed) and apply (applied). The former refers to the status of the log after the log has been copied to most nodes; while the latter refers to the node applying the log to the state machine, which truly affects the node status.
3. Split-brain problem
The raft algorithm guarantees that at most one leader can be elected in any term. There can only be one leader in a replica set at any time. There is more than one leader in the system at the same time, which is called brain split. This is a very serious problem and will cause data coverage loss. In raft, two points guarantee this property:
- A node can only cast one vote at most in a certain term.
- Only the node that receives the majority vote will become the leader
Therefore, there must be only one leader in a certain term. However, in the case of network partition, there may be two leaders, but the terms of the two leaders are different.
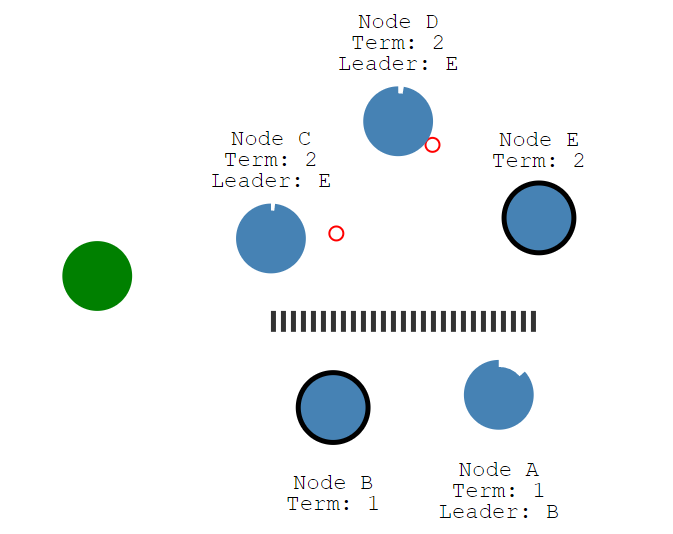
In the above figure, Node A, B and Node C, D, E may be separated due to network problems, so Node C, D, E cannot receive messages from the leader (Node B). After the election time, Node C, D, and E will be elected in stages. Since the majority condition is met, Node E becomes the leader of term 2. Therefore, there seem to be two leaders in the system: Node B in term 1 and Node E in term 2. Node B’s term is older, but since it cannot communicate with the Majority node, Node B will still consider itself the leader. At this time, a client sent a write request to Node B. Node B found that it could not copy the log entry to the majority node, so it would not tell the client that the write was successful. If the client sends a write request to C, Node C can copy the log entry to the majority node, so the network partition where Node C is located can receive the request normally. When the network is repaired, Node B and Node A find that the Term they are in is 1, which is smaller than the term of Node C, so they will degenerate into followers and synchronize cluster data.