1. Why is the preemption mechanism needed?
When a pod fails to be scheduled, it is temporarily in the pending state. The scheduler will not reschedule the pod until the pod is updated or the cluster status changes. However, in actual business scenarios, there will be a distinction between online and offline services. If the pod of the online service fails to be scheduled due to insufficient resources, it is necessary for the offline service to drop part of the resources to provide resources for the online service. That is, the online service must preempt the offline service. Business resources require the scheduler’s priority and preemption mechanism. This mechanism solves the problem of what to do when pod scheduling fails. If the pod has a higher priority, it will not be “on hold” at this time. Instead, it will “crowd out” some low-priority pods on a certain node, so that high-priority pods can be scheduled successfully.
2. How to use the preemption mechanism
1. Create PriorityClass object:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: ""
2. Declare to use the existing priorityClass object in deployment, statefulset or pod.
Apply to Pod:
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx-a
name: nginx-a
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx-a
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
memory: "64Mi"
cpu: 5
limits:
memory: "128Mi"
cpu: 5
priorityClassName: high-priority
Apply to Deployment:
template:
spec:
containers:
- image: nginx
name: nginx-deployment
priorityClassName: high-priority
3. Related processes
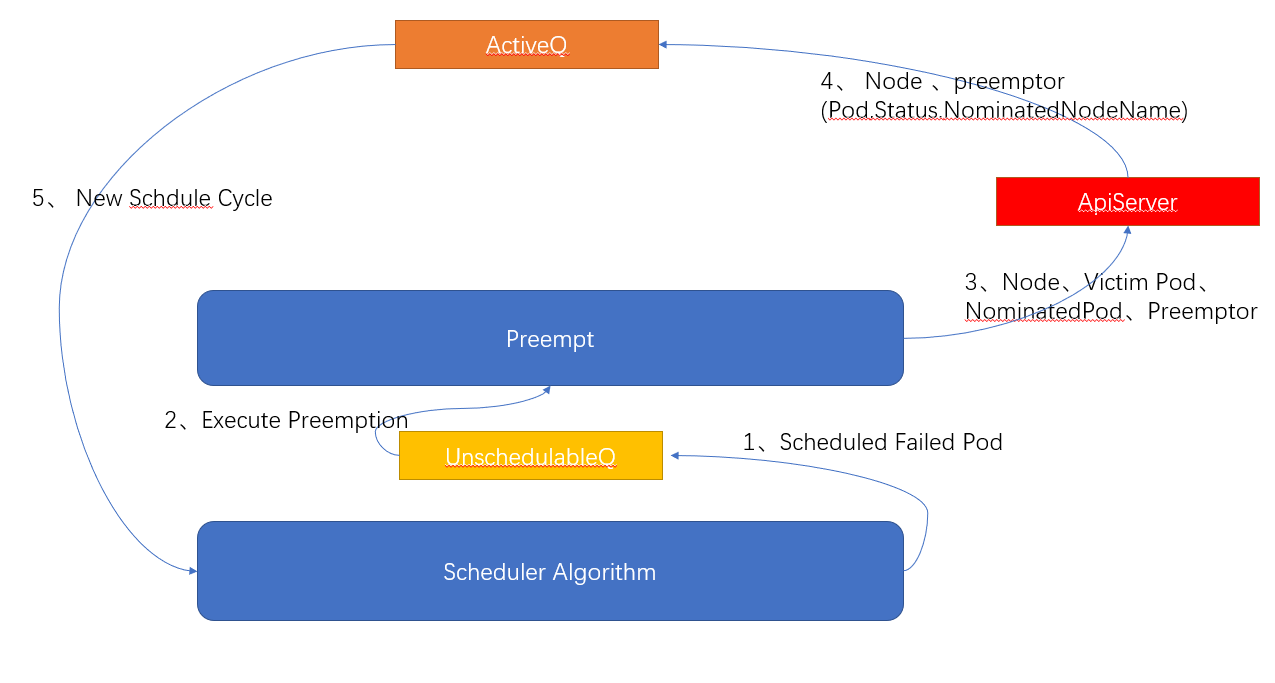
- Put the Pod that failed to be scheduled into the UnscheduleableQ queue.
- If preemption is enabled, the preemption algorithm Preempt is executed.
- The preemption algorithm Preempt returns successful node, pods to be deleted (victims), preempted Pod (NominatedPod) and preemptor Pod (Preemptor). Set the pod.Status.NominatedNodeName field of the preemptor Pod to the name of the successfully preempted node and submit it to ApiServer. And remove preempted pods (victims) with low priority on this node. At the same time, clear the pod.Status.NominatedNodeName field of NominatedPod and submit it to ApiServer. Finally, put the preemptor Pod (Preemptor) into ActiveQ and wait for the next scheduling.
//k8s.io/kubernetes/pkg/scheduler/scheduler.go:352
func (sched *Scheduler) preempt(pluginContext *framework.PluginContext, fwk framework.Framework, preemptor *v1.Pod, scheduleErr error) (string, error) {
// get pod info
preemptor, err := sched.PodPreemptor.GetUpdatedPod(preemptor)
if err != nil {
klog.Errorf("Error getting the updated preemptor pod object: %v", err)
return "", err
}
// Execute preemption
node, victims, nominatedPodsToClear, err := sched.Algorithm.Preempt(pluginContext, preemptor, scheduleErr)
if err != nil {
......
}
var nodeName = ""
if node != nil {
nodeName = node.Name
// Update the scheduler cache and bind nodename to the preemptor, that is, set pod.Status.NominatedNodeName
sched.SchedulingQueue.UpdateNominatedPodForNode(preemptor, nodeName)
// Submit pod info to apiserver
err = sched.PodPreemptor.SetNominatedNodeName(preemptor, nodeName)
if err != nil {
sched.SchedulingQueue.DeleteNominatedPodIfExists(preemptor)
return "", err
}
// Delete preempted pods
for _, victim := range victims {
if err := sched.PodPreemptor.DeletePod(victim); err != nil {
return "", err
}
......
}
}
// Delete the NominatedNodeName field of preempted pods
for _, p := range nominatedPodsToClear {
rErr := sched.PodPreemptor.RemoveNominatedNodeName(p)
if rErr != nil {
......
}
}
return nodeName, err
}
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:320
func (g *genericScheduler) Preempt(pluginContext *framework.PluginContext, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
fitError, ok := scheduleErr.(*FitError)
if !ok || fitError == nil {
return nil, nil, nil, nil
}
// Determine whether the pod supports preemption. If the pod has already preempted a low-priority pod and the preempted pod is in the terminating state, preemption will not continue.
if !podEligibleToPreemptOthers(pod, g.nodeInfoSnapshot.NodeInfoMap, g.enableNonPreempting) {
return nil, nil, nil, nil
}
// Get node list from cache
allNodes := g.cache.ListNodes()
if len(allNodes) == 0 {
return nil, nil, nil, ErrNoNodesAvailable
}
// Filter nodes that fail to execute the predicates algorithm as candidate nodes for preemption
potentialNodes := nodesWherePreemptionMightHelp(allNodes, fitError)
// If the filtered candidate node is empty, return the preemptor as nominatedPodsToClear
if len(potentialNodes) == 0 {
return nil, nil, []*v1.Pod{pod}, nil
}
// get PodDisruptionBudget objects
pdbs, err := g.pdbLister.List(labels.Everything())
if err != nil {
return nil, nil, nil, err
}
// Filter out the list of nodes that can be preempted
nodeToVictims, err := g.selectNodesForPreemption(pluginContext, pod, g.nodeInfoSnapshot.NodeInfoMap, potentialNodes, g.predicates,
g.predicateMetaProducer, g.schedulingQueue, pdbs)
if err != nil {
return nil, nil, nil, err
}
// If there is an extender, execute it
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
if err != nil {
return nil, nil, nil, err
}
// Choose the best node
candidateNode := pickOneNodeForPreemption(nodeToVictims)
if candidateNode == nil {
return nil, nil, nil, nil
}
// Remove Nominated from low-priority pods, update these pods, move them to the activeQ queue, and let the scheduler
// Re-bind node for these pods
nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name)
if nodeInfo, ok := g.nodeInfoSnapshot.NodeInfoMap[candidateNode.Name]; ok {
return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
return nil, nil, nil, fmt.Errorf(
"preemption failed: the target node %s has been deleted from scheduler cache",
candidateNode.Name)
}
- In the next scheduling cycle, kube-scheduler obtains the preemptor Pod from Active Q and re-executes scheduling.